ElevenLabs Unveils V3 AI Voice Model with 70+ Languages and Emotional Control
ElevenLabs, a pioneer in AI voice technology, has officially introduced its Eleven v3 (Alpha) text-to-speech model—the company's most expressive AI voice system to date. This release marks a significant leap in speech synthesis, offering creators and developers unprecedented control over vocal emotion and tone.

A New Standard for Natural Speech
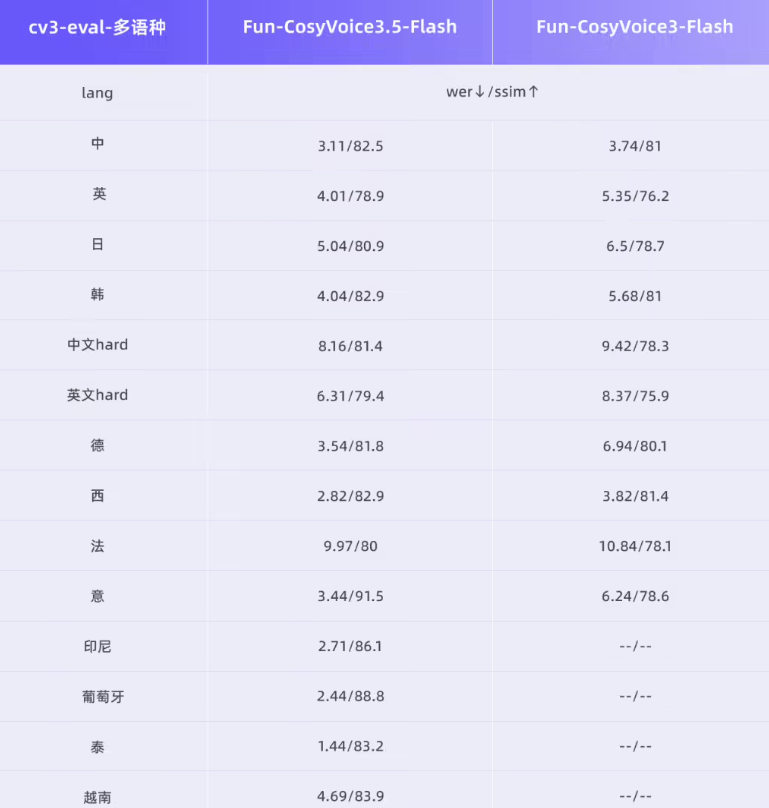
The v3 architecture demonstrates deeper text comprehension, producing remarkably human-like vocal expressions. Unlike previous iterations, this model supports over 70 languages and handles complex multi-character dialogues with ease. It realistically mimics conversational nuances—tone shifts, emotional inflections, and even interruptions—that were previously challenging for AI systems.
Emotional precision sets v3 apart. Creators can now insert simple tags like [sad], [angry], or [whispers] directly into text to shape vocal delivery. The system even processes non-verbal cues such as laughter or sighs, opening new possibilities for dynamic audio content.
Empowering Creative Industries
From audiobook narration to video game character voices, v3's applications are transformative. The model supports 32 distinct speaker profiles, making it ideal for projects requiring diverse vocal ranges. Educational content developers and customer service platforms are already exploring its potential for creating more engaging interactions.
Early adopters in the film industry report the model saves weeks of studio time for preliminary dubbing work. "The emotional range is astonishing," noted one beta tester working on an animated feature. "We're getting first-pass vocals that often require minimal adjustment."
Accessibility and Future Developments
Throughout June, ElevenLabs offers an 80% discount on v3 access to encourage experimentation. The company plans to release a public API soon, with developers able to request early access through sales channels.
While optimized for pre-recorded content currently, ElevenLabs confirms a real-time version of v3 is in development. For immediate conversational needs, they recommend sticking with their v2.5Turbo or Flash models.
Shaping the Voice Technology Landscape
The launch intensifies competition in the rapidly evolving AI voice sector. ElevenLabs' technology already powers major audiobook platforms and virtual assistants; v3 strengthens their position against rivals like OpenAI's Whisper and Google's Gemini systems.
Social media buzz suggests many consider v3 the new gold standard for text-to-speech quality. One industry analyst remarked, "The gap between synthetic and human speech narrows dramatically with this release."
Looking ahead, ElevenLabs promises continued enhancements including reduced latency and broader language support. As these tools become more accessible, they may redefine how we produce digital content across media formats.
Key Points
- Supports 70+ languages with improved natural speech patterns
- Introduces emotional tagging (e.g.,
[happy],[sarcastic]) for precise vocal control - Enables multi-speaker scenarios with 32 distinct voice profiles
- Currently in public Alpha with 80% June discount for early adopters
- Real-time conversation version under development