Ditch the Blurry Boxes! SegVG Gives AI a Pixel-Perfect Edge
Ditch the Blurry Boxes! SegVG Gives AI a Pixel-Perfect Edge
In the realm of AI vision, object localization has long been like using a pair of fogged-up glasses. Sure, traditional algorithms can slap on some rough 'bounding boxes' around objects, but it’s like trying to describe your best friend by saying, “Uh, they’re about 6 feet tall and… kinda wide?” Not exactly helpful, right?
Well, it’s 2024, and we’re done with those outdated tricks! A squad of brainiacs from the Illinois Institute of Technology, Cisco Research, and the University of Central Florida have cooked up something revolutionary. Meet SegVG, a localization framework that’s about to slap AI’s nearsightedness out of the park and give it some pixel-perfect clarity!
SegVG: Putting AI in High-Definition!
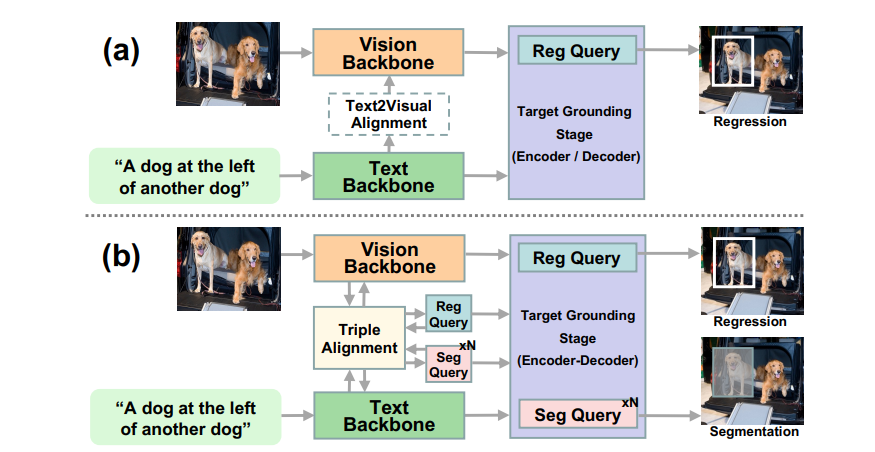
So, what makes SegVG so special? Traditional AI algorithms only work with bounding boxes, which are pretty much the equivalent of showing AI a blurry shadow and expecting it to know what’s up. SegVG, though, is strapping on some igh-def glassesand giving AI the power to see every single pixel. That’s right—no more guessing games!
Instead of just tossing a box around an object, SegVG transforms that boxy info into segmentation signals. Think of it like upgrading from an 8-bit pixelated game to 4K ultra-HD. AI’s vision is now razor-sharp, and it can pick up on the tiniest details.
The Magic Behind the Curtain: Multi-Task Decoder
Now, let’s talk tech. At the heart of SegVG is something called a "multi-layer multi-task encoder-decoder". Yeah, it sounds fancy, but here’s the deal—imagine it as a super-charged microscope. This baby can zoom in and out, using different 'lenses' for bounding box regression and segmentation tasks. It’s like having two sets of eyes working together to make sure nothing slips by unnoticed.
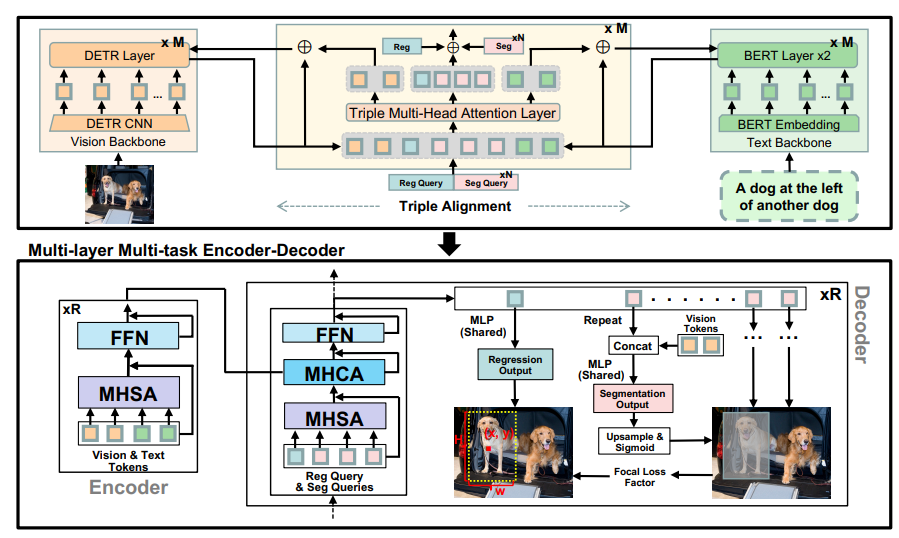
But wait, there’s more! SegVG packs a triplet alignment module. In simpler terms: it’s like a translator for AI, teaching it to understand the 'language' of pre-training parameters and query embeddings. Through this triplet attention mechanism, SegVG aligns the AI’s queries, text, and visual info into one clear channel. It’s like finally getting everyone singing in tune!
How Well Does It Work?
You’re probably thinking, “Okay, sounds cool, but does it actually work?” Oh, it works lright The experts behind SegVG put it to the test on five popular datasets, including the notoriously tricky RefCOCO+ and RefCOCOg. Guess what? SegVG crushed it, outperforming the usual suspects in the algorithm world!
And that’s not all. SegVG can even give you confidence scores for its predictions. So, if AI is feeling a little 'meh' about its decision, it’ll let you know. This is clutch in fields like medical imaging where a wrong guess could be catastrophic. If AI’s confidence dips, it’s time to call in the humans.
Open Source Awesomeness
Here’s the cherry on top: SegVG is open-source. That means developers and researchers all over the world can jump in, tweak it, and push the boundaries of AI vision tech even further. Collaboration, people—it’s the future!
Want to take a closer look? Check out the paper here and the code on GitHub here.
Summary
Traditional AI algorithms rely on outdated, blurry bounding boxes for object recognition.
SegVG introduces pixel-level accuracy, giving AI high-definition vision.
The framework uses a multi-layer, multi-task encoder-decoder to enhance localization precision.
It also includes a triplet alignment module to improve AI’s understanding of pre-training parameters and query embeddings.
SegVG is open-source, encouraging community collaboration to further advance AI vision tech.