DeepSeek Unveils Breakthrough in Large Model Training Efficiency
Artificial intelligence research firm DeepSeek has released a comprehensive paper revealing its advanced methodologies for efficient large model training. The publication, which has garnered widespread industry attention, demonstrates how the company achieves remarkable performance while dramatically reducing computational costs.
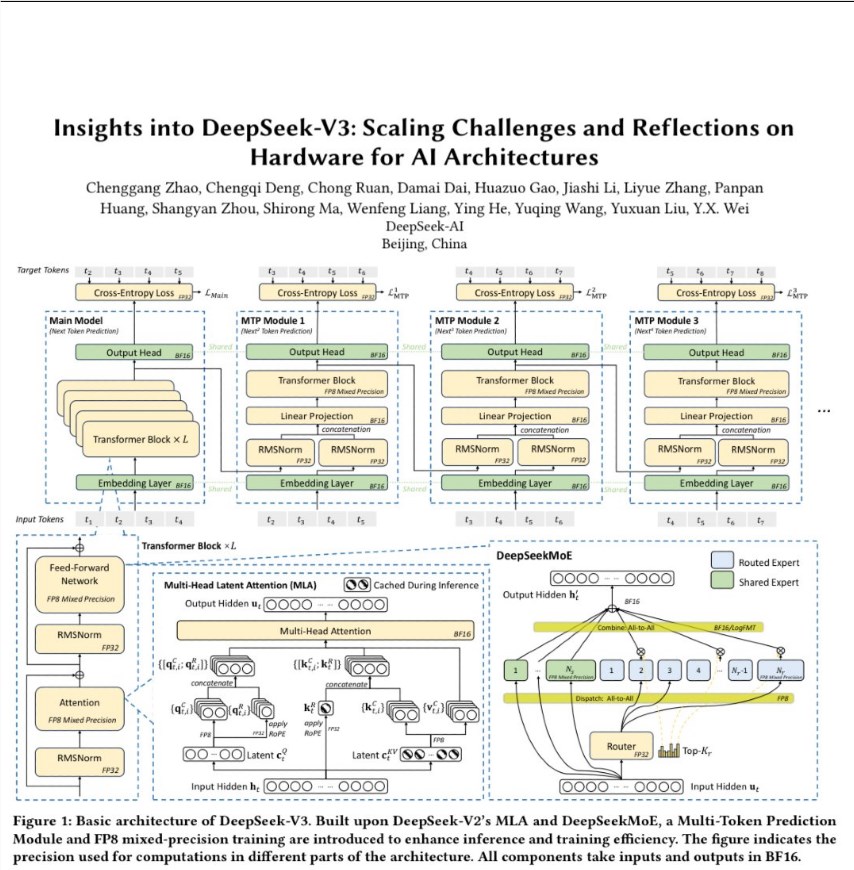
Software Innovations The paper highlights several software breakthroughs including Multi-Head Latent Attention (MLA), which slashes memory usage during inference by up to 40%. DeepSeek's FP8 mixed precision training maintains numerical stability while accelerating calculations, and their proprietary DeepEP communication library optimizes Expert Parallelism with support for FP8 operations - particularly beneficial for Mixture of Experts (MoE) models.
Hardware Advancements On the hardware front, DeepSeek employs a Multi-Rail Fat Tree network architecture combined with Ethernet RoCE switches. This configuration boosts cluster performance while minimizing communication overhead - critical for large-scale distributed training across thousands of GPUs.
Hybrid Optimization Techniques The research team developed IBGDA (InfiniBand-based Group Data Aggregation) to address cross-node MoE training bottlenecks. Their 3FS (Fire-Flyer File System) maximizes SSD and RDMA network bandwidth, delivering unprecedented data access speeds for AI workloads.
These innovations enabled DeepSeek to train its V3 model using just 2.78 million GPU hours on 2,048 NVIDIA H800 GPUs - achieving performance comparable to leading closed-source models at a fraction of the cost. The company's co-design approach, integrating algorithmic improvements with framework and hardware optimizations, demonstrates how open-source AI can compete with proprietary solutions.
The paper provides valuable insights for researchers and engineers working on large language models. By sharing these techniques openly, DeepSeek aims to accelerate progress across the AI community while establishing itself as a leader in efficient model development.
Key Points
- DeepSeek's MLA technique reduces inference memory usage by 40%
- FP8 mixed precision maintains accuracy while boosting efficiency
- Novel network topology cuts communication overhead in large clusters
- Training costs reduced dramatically without sacrificing performance
- Open-source approach challenges proprietary model dominance