DeepSeek's NSA Tech Wins ACL 2025 Best Paper, Boosts Text Processing 11x
DeepSeek's Revolutionary Text Processing Technology Earns Top AI Honor
At the prestigious ACL 2025 conference, a research team led by Dr. Wenfeng Liang from DeepSeek, in collaboration with Peking University, claimed the Best Paper Award among a record-breaking 8,360 submissions. Their winning paper introduces Native Sparse Attention (NSA), a breakthrough mechanism that dramatically improves long-text processing efficiency while maintaining superior accuracy.
The NSA Breakthrough
The team's Native Sparse Attention technology represents a quantum leap in natural language processing capabilities. Through innovative algorithmic and hardware optimizations, NSA achieves:
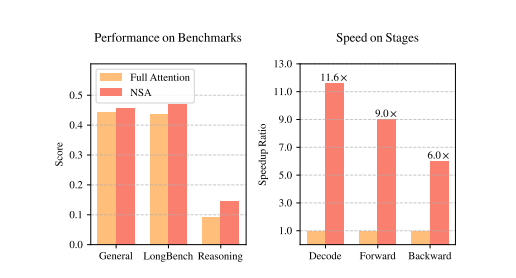
- 11.6x faster decoding speeds for 64k-length texts
- 9x improvement in forward propagation
- 6x acceleration in backward propagation

Technical Innovation Explained
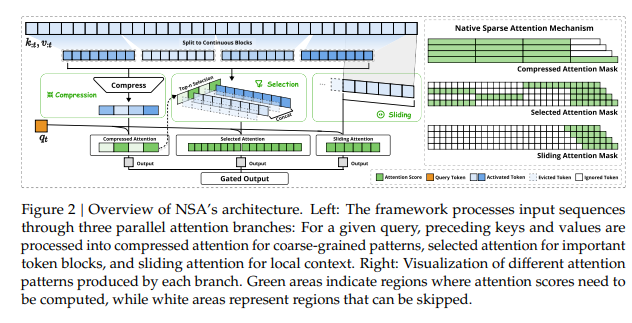
The NSA mechanism employs a sophisticated dynamic hierarchical sparsity strategy combined with three specialized attention branches:
- Compression Attention: Summarizes global information efficiently
- Selective Attention: Focuses computational resources on critical word blocks
- Sliding Attention: Maintains local context integrity
This architecture enables native trainability on modern GPU hardware while supporting context lengths up to an unprecedented 1 million tokens.
Performance Benchmarks
The 27B parameter NSA model demonstrated remarkable results:
- Outperformed traditional full-attention models in 7 out of 9 evaluation metrics
- Showed particular strength in complex tasks like:
- Multi-hop question answering
- Advanced code understanding
- Long-document comprehension
The technology maintains accuracy while delivering dramatic speed improvements, addressing one of NLP's most persistent challenges.
Future Implications
This research opens new possibilities for:
- Large-scale document analysis
- Advanced AI assistants
- Complex code generation
- Scientific literature processing
The paper establishes NSA as a foundational technology for next-generation language models.
Paper Reference: https://arxiv.org/pdf/2502.11089
Key Points:
- 🏆 Won ACL 2025 Best Paper among record 8,360 submissions
- ⚡ Achieves up to 11x faster text processing
- 🧠 Supports context lengths of 1 million tokens
- 🔍 Outperforms traditional models in most benchmarks
- 🤖 Three specialized attention branches enable breakthrough efficiency