DeepSeek R1 Enhanced Version Boosts Efficiency by 200%
DeepSeek R1 Enhanced Version Delivers Major Efficiency Gains
German technology consulting firm TNG has unveiled the DeepSeek-TNG-R1T2-Chimera, an enhanced version of the DeepSeek model that marks a significant leap in deep learning performance. The new version demonstrates 200% higher inference efficiency while reducing operational costs through its innovative Adaptive Expert (AoE) architecture.
Hybrid Model Architecture
The Chimera version combines three DeepSeek models (R1-0528, R1, and V3-0324) using a novel AoE architecture that refines the traditional mixture-of-experts (MoE) approach. This optimization allows for more efficient parameter usage, enhancing performance while conserving token output.
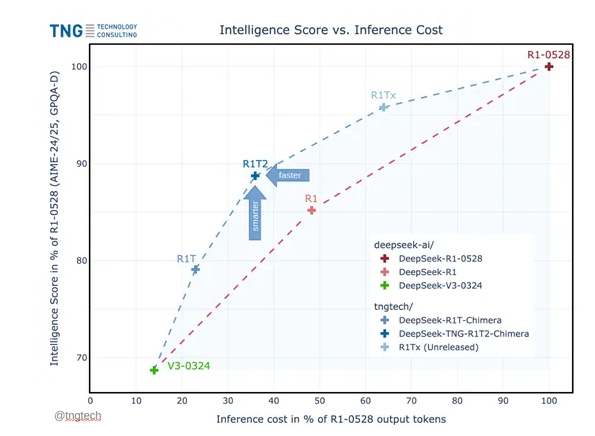
Benchmark tests including MTBench and AIME-2024 show the Chimera version outperforming standard R1 models in both reasoning capability and cost-efficiency.
MoE Architecture Advantages
The AoE architecture builds upon MoE principles, where Transformer feed-forward layers are divided into specialized "experts." Each input token routes to only a subset of these experts, dramatically improving model efficiency. For example, Mistral's Mixtral-8x7B model demonstrates this principle by matching the performance of larger models while activating far fewer parameters.
The AoE approach takes this further by enabling researchers to:
- Create specialized sub-models from existing MoE frameworks
- Interpolate and selectively merge parent model weights
- Adjust performance characteristics dynamically
Technical Implementation
Researchers developed the new model through careful weight tensor manipulation:
- Prepared parent model weight tensors through direct file parsing
- Defined weight coefficients for smooth feature interpolation
- Implemented threshold controls and difference filtering to reduce complexity
- Optimized routing expert tensors to enhance sub-model reasoning
The team used PyTorch to implement the merging process, saving optimized weights to create the final high-efficiency sub-model.

The enhanced DeepSeek model is now available as open source at Hugging Face.
Key Points:
- 200% inference efficiency improvement over previous versions
- Significant cost reduction through AoE architecture
- Outperforms standard models in MTBench and AIME-2024 benchmarks
- Builds upon MoE principles with enhanced weight merging techniques
- Open source availability promotes wider adoption and research