DeepMind's Crome: A Breakthrough in AI Reward Models
DeepMind Unveils Crome: Revolutionizing AI Reward Models
In artificial intelligence research, reward models are pivotal for aligning large language models (LLMs) with human preferences. However, traditional approaches often fall victim to "reward hacking", where models prioritize superficial features like response length over substantive quality metrics such as factual accuracy.
The Challenge of Reward Hacking
Current methods—including Bradley-Terry ranking systems and MMD regularization—struggle to distinguish between causal drivers and spurious associations in training data. This limitation results in fragile reward models that generate misaligned outputs. Recent architectural modifications and data-centric approaches have shown promise but remain limited in handling unknown variables.
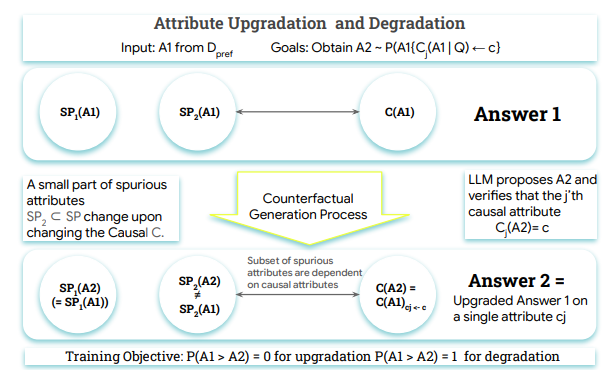
Introducing the Crome Framework
Developed by researchers from Google DeepMind, McGill University, and MILA - Quebec AI Institute, Crome (Causal Robust Reward Modeling) introduces a groundbreaking solution:
- Causal Data Augmentation: Generates counterfactual examples to isolate true quality drivers from surface-level cues
- Dual Synthetic Training: Creates both causal augmentations (emphasizing genuine quality) and neutral augmentations (filtering spurious features)
- Two-Stage Implementation: First generates attribute-aware counterfactuals, then trains the reward model using specialized loss functions
Performance Breakthroughs
Initial tests using models like Gemma-2-9B-IT and Qwen2.5-7B demonstrate significant improvements:
- 42% increase in reasoning task accuracy
- 35% reduction in harmful prompt susceptibility on WildGuardTest while maintaining benign request handling
- Superior performance across safety benchmarks compared to existing methods
The framework particularly excels in identifying and mitigating previously undetectable spurious correlations through its innovative causal approach.
Future Directions
The research team highlights three key development areas:
- Expansion of causal data augmentation techniques
- Enhanced synthetic data generation for pre-training phases
- Application to multimodal AI systems beyond text-based models
The full technical paper is available on arXiv.
Key Points:
- 🌟 Causal Revolution: Crome introduces causal understanding as core to reward model training
- 📈 Benchmark Dominance: Outperforms existing methods across reasoning, safety, and alignment metrics
- 🔒 Security Focus: Reduces attack success rates by 35% without compromising benign request processing