CMU and Meta Introduce VQAScore for Evaluating AI Models
CMU and Meta Introduce VQAScore for Evaluating AI Models
Generative AI technology is advancing rapidly, yet evaluating its performance presents ongoing challenges. As numerous models emerge with impressive capabilities, a critical question arises: how should the effectiveness of text-to-image models be assessed?
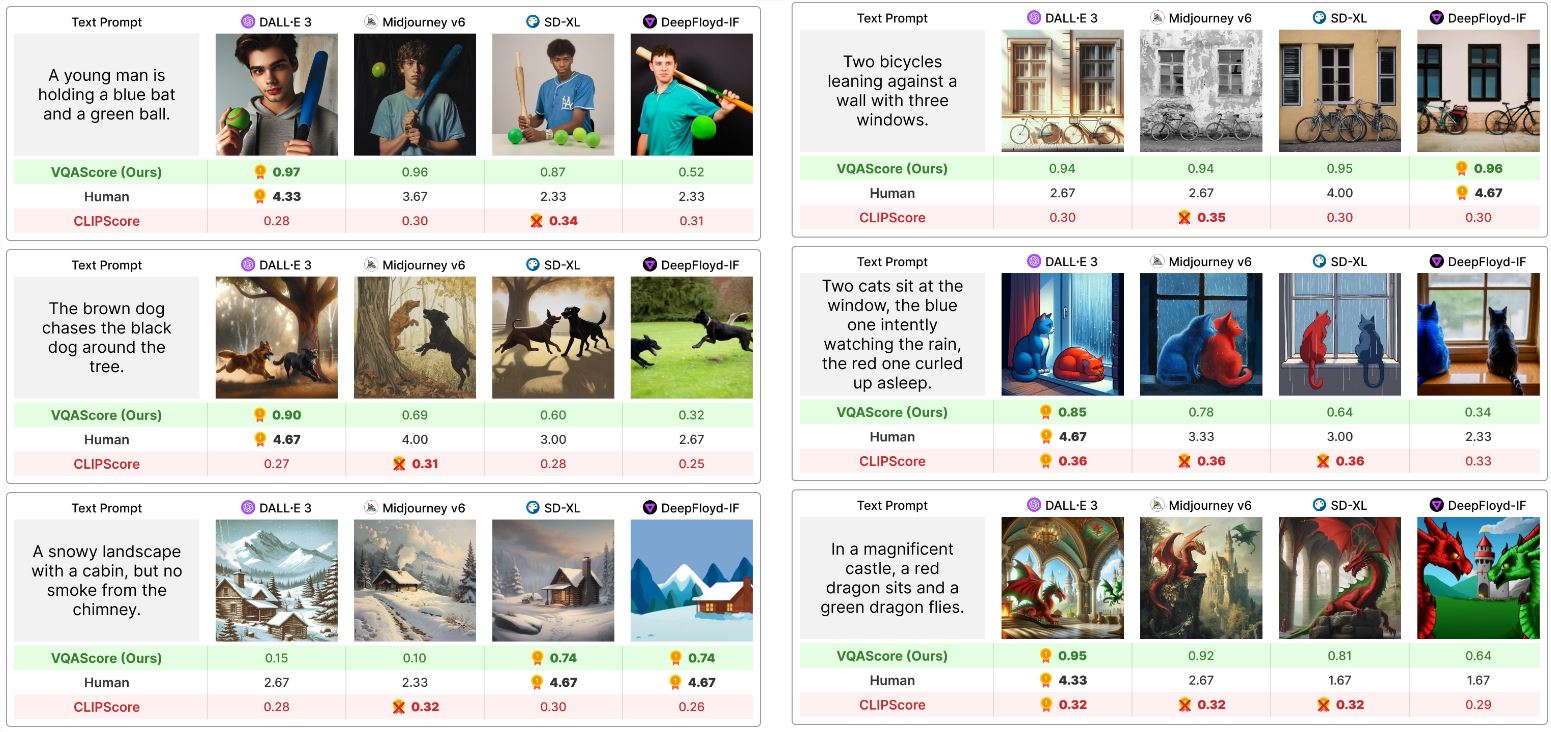
Traditional evaluation methods often rely on human visual inspection, which is inherently subjective, or utilize simplistic metrics like CLIPScore. These approaches frequently fail to capture the complexities inherent in nuanced text prompts, such as the relationships between objects and logical reasoning. The result is often inaccurate evaluations, where models generate images that deviate significantly from expectations but still receive high scores.
To tackle this challenge, researchers from Carnegie Mellon University and Meta have collaborated to develop a new evaluation scheme known as VQAScore. This innovative approach leverages Visual Question Answering (VQA) models to assess text-to-image models systematically.
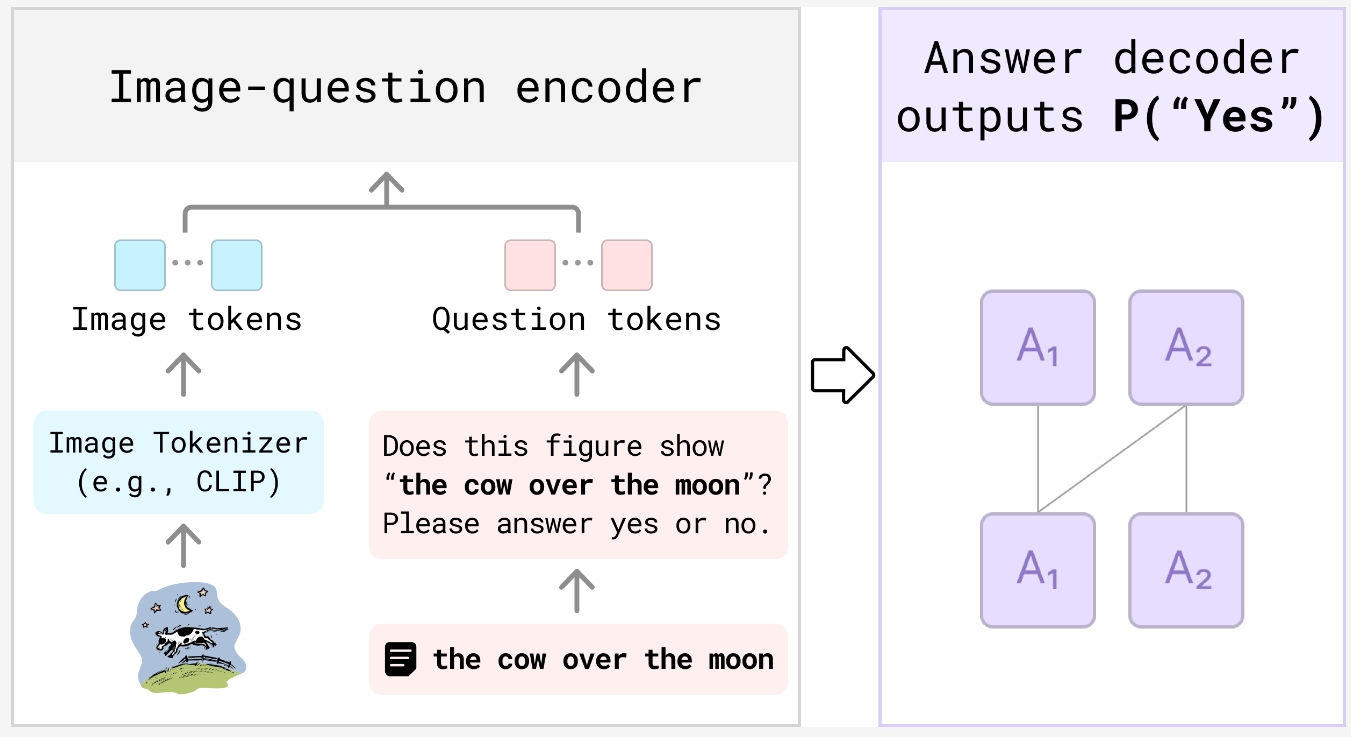
How VQAScore Works
VQAScore operates by converting a text prompt into a straightforward question, such as “Is there a cat chasing a mouse in this image?” The generated image, along with the question, is then processed by the VQA model. The model determines whether the answer is “yes” or “no,” and VQAScore assigns a score to the text-to-image model based on the likelihood of receiving a “yes” answer from the VQA model.
Though the methodology appears simple, its results are remarkably effective. Researchers tested VQAScore across eight different text-to-image evaluation benchmarks and found that its accuracy and reliability significantly surpassed those of traditional methods, even competing with evaluations based on advanced models such as GPT-4V.
Moreover, VQAScore is versatile; it is applicable not only to text-to-image evaluations but also to text-to-video and text-to-3D model evaluations. This versatility stems from the underlying VQA model, which is capable of processing various types of visual content.

GenAI-Bench: A New Evaluation Benchmark
In addition to VQAScore, the research team has established a new evaluation benchmark called GenAI-Bench. This benchmark encompasses 1,600 complex text prompts that test various visual-language reasoning abilities, including comparison, counting, and logical reasoning. The researchers also collected over 15,000 human annotations to evaluate the performance of different text-to-image models.
In summary, the introduction of VQAScore and GenAI-Bench revitalizes the field of text-to-image generation. VQAScore provides a more accurate and reliable method for evaluating AI models, enabling researchers to better understand the strengths and weaknesses of various systems. Meanwhile, GenAI-Bench offers a comprehensive and challenging framework that encourages the development of more intelligent and human-like models.
While VQAScore represents a significant advancement, it is not without limitations. Currently, it primarily relies on open-source VQA models, whose performance may not match that of closed-source models like GPT-4V. Future improvements in VQA models are expected to enhance the effectiveness of VQAScore.
For more information, visit the project page: VQAScore Project
Key Points
- VQAScore introduces a novel method for evaluating text-to-image models using Visual Question Answering.
- The new evaluation benchmark, GenAI-Bench, includes 1,600 complex prompts and over 15,000 human annotations.
- VQAScore outperforms traditional evaluation methods, providing more accurate assessments of generative AI models.