ByteDance Unveils Seed LiveInterpret 2.0: A Breakthrough in AI Translation
ByteDance's Seed LiveInterpret 2.0 Redefines AI Translation
ByteDance's research division has made a significant leap in artificial intelligence with the release of Seed LiveInterpret 2.0, an end-to-end simultaneous interpretation model that challenges the capabilities of human interpreters.
Revolutionary Features
The new system represents a major advancement in machine translation technology with three groundbreaking capabilities:
- Human-like accuracy approaching professional interpreter quality
- Ultra-low latency of just 2-3 seconds
- Real-time voice cloning that preserves the speaker's vocal characteristics
Technical Breakthroughs
The model is built on a full-duplex end-to-end speech generation and understanding framework, enabling it to process multiple voice inputs simultaneously while maintaining bidirectional Chinese-English translation capabilities. Unlike traditional systems that require sequential processing, Seed LiveInterpret 2.0 mimics human interpreters by listening and speaking simultaneously.
"This isn't just incremental improvement—it's a paradigm shift in how machines handle language," explains the technical report. "Our model achieves what we call 'true simultaneous interpretation' where comprehension and production happen in parallel."
Performance Metrics
In rigorous testing scenarios:
- Achieved 80% accuracy for single-speaker translations
- Maintained 70% accuracy in complex group meeting environments
- Demonstrated remarkable adaptability to different speech patterns and literary characters (from Zhu Bajie to Lin Daiyu)
The system's voice cloning capability requires no prior voice samples, learning vocal characteristics entirely through real-time interaction—a feature the team calls "zero-shot voice cloning."
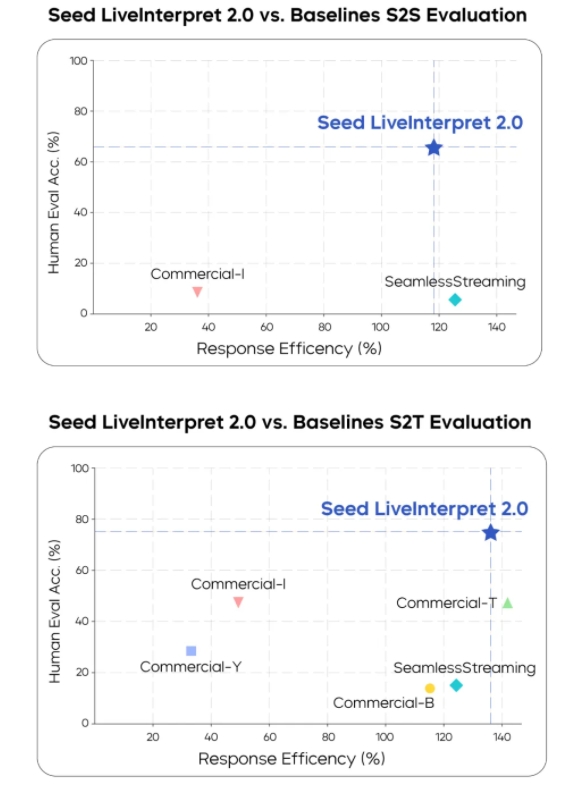
Industry-Leading Evaluation Results
The model was tested against the RealSI dataset, containing 10 domains of Chinese-English content in both directions:
- In speech-to-text evaluation: scored 74.8/100 (58% higher than second-place systems)
- In speech-to-speech evaluation: achieved 66.3/100, surpassing all competitors
- Maintained consistent latency below 2.53 seconds across all test scenarios
Key Advantages Over Traditional Systems
- Unprecedented speed: 60% faster than conventional machine interpretation systems
- Contextual awareness: Adapts output rhythm based on speech complexity
- Emotional resonance: Preserves speaker vocal qualities for more natural communication
- Scalability: Handles both brief statements and extended speeches (tested up to 40-second inputs)
- Domain flexibility: Performs equally well across technical, literary, and conversational content
The technical team emphasizes that these advancements don't just improve machine translation—they redefine what's possible in cross-cultural communication.
Key Points:
- ByteDance releases next-generation AI interpretation model with human-like capabilities
- System achieves industry-leading accuracy scores while maintaining sub-3-second latency
- Revolutionary voice cloning works without prior samples through real-time learning
- Outperforms all existing systems in professional evaluations across multiple metrics
- Technical details available in published paper and project homepage