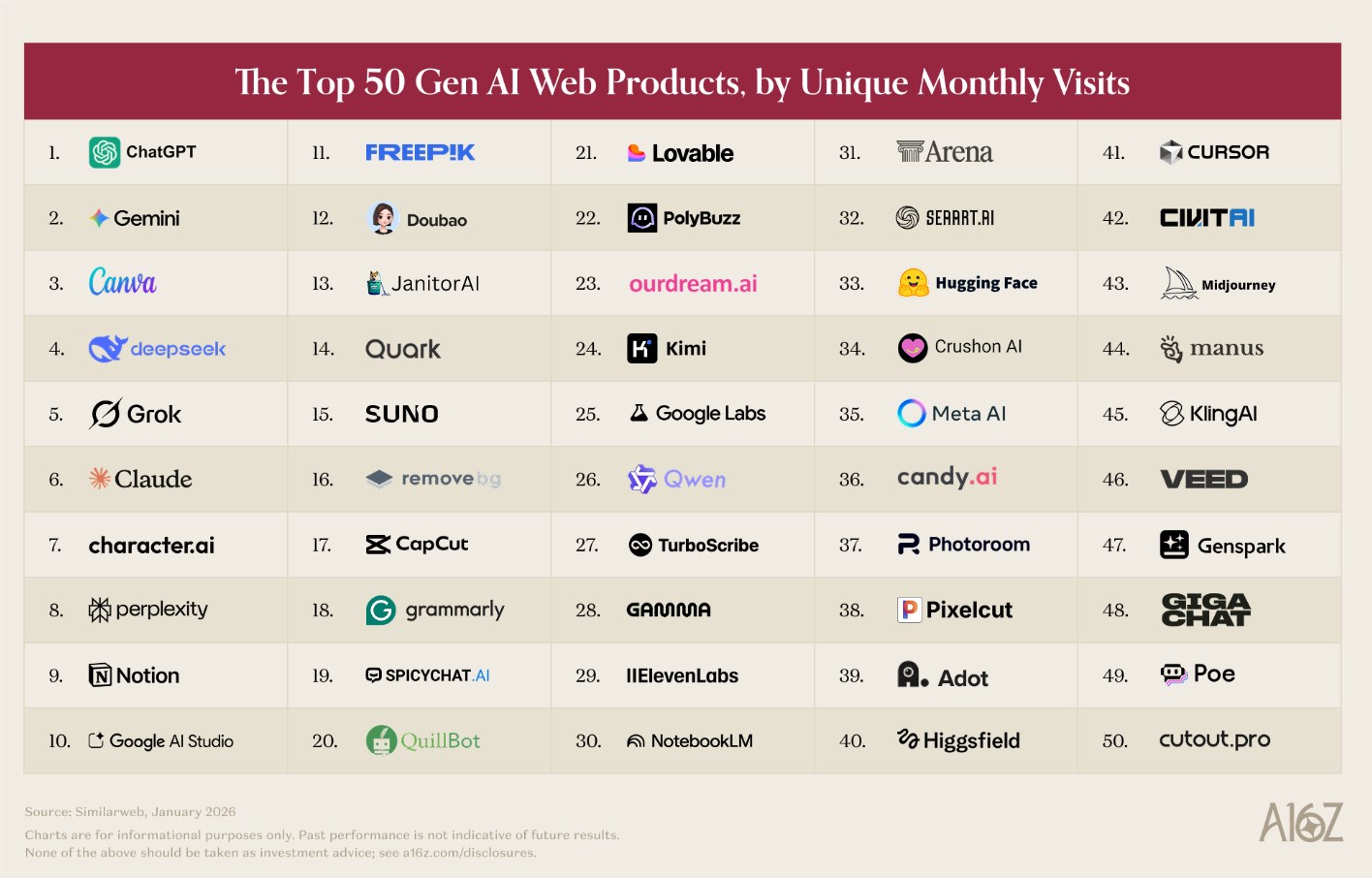
ByteDance Unveils Infinity Framework for Image Generation
ByteDance Unveils Infinity Framework for High-Resolution Image Generation
In the realm of image generation, creating high-resolution and realistic images poses significant challenges, particularly in the text-to-image synthesis process. Traditional methods predominantly rely on diffusion models and variational autoregressive (VAR) frameworks. While these models are capable of producing high-quality images, they demand extensive computational resources, limiting their applicability for real-time use. Furthermore, VAR models often suffer from error accumulation when processing discrete tokens, which can lead to a loss of detail and a decline in image realism.
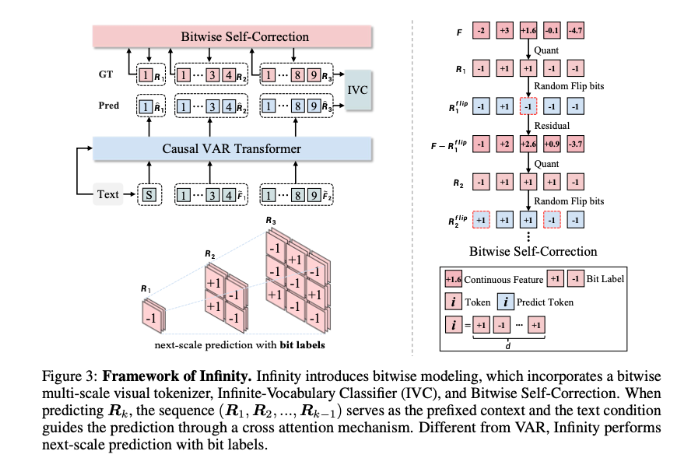
To address these limitations, a research team at ByteDance has developed a groundbreaking framework known as "Infinity." This innovative approach aims to enhance the efficiency and quality of text-to-image synthesis, marking a significant advancement in generative AI technologies.
Key Innovations of Infinity Framework
The Infinity framework improves image generation by introducing bit-level tokenization in place of traditional index-level tokenization. This shift significantly reduces quantization errors, resulting in more realistic images. Additionally, Infinity employs an Infinite Vocabulary Classifier (IVC), expanding the token vocabulary to (2^{64}), which substantially lowers memory and computational requirements.
Architecture of Infinity
The Infinity architecture comprises three primary components:
- Bit-Level Multi-Scale Quantization Tokenizer: This component converts image features into binary tokens, minimizing computational overhead.
- Transformer-Based Autoregressive Model: This model predicts residuals based on text prompts and prior outputs, enhancing the model's predictive accuracy.
- Self-Correcting Mechanism: This innovative feature introduces random bit flips during training, bolstering the model's resilience to errors. The research team utilized extensive datasets such as LAION and OpenImages for training, successfully increasing image resolution from 256×256 to 1024×1024.
Performance Evaluation
Upon evaluation, the Infinity framework exhibited outstanding performance on critical metrics, achieving a GenEval score of 0 and a Fréchet Inception Distance (FID) reduced to 3.48. These results underscore the framework's advancements in both generation speed and image quality. Notably, Infinity can generate high-resolution images of 1024×1024 pixels in just 0.8 seconds, showcasing its efficiency and reliability. The images produced are not only visually striking and rich in detail but also adept at responding to complex text instructions, as evidenced by high human preference scores.
The introduction of Infinity sets a new benchmark in the field of high-resolution text-to-image synthesis. By effectively addressing longstanding issues related to scalability and detail quality through its innovative design, Infinity represents a substantial leap forward in the evolution of generative AI.
For more technical details, the research paper is available at: Infinity Framework Research Paper
Conclusion
ByteDance's Infinity framework is poised to transform the landscape of image generation, offering a solution to the technical challenges that have hindered the field. With its advanced capabilities, Infinity is likely to have far-reaching implications for various applications requiring high-quality image synthesis.
Key Points
- Innovative Framework Infinity: The Infinity framework launched by ByteDance significantly enhances the efficiency of high-resolution image generation through bit-level tokenization and an infinite vocabulary classifier.
- Outstanding Performance: Infinity surpasses existing models on key evaluation metrics, capable of generating high-quality images of 1024×1024 in just 0.8 seconds.
- Realistic Details and Responsiveness: The generated images are not only visually realistic but also accurately respond to complex text prompts, demonstrating high human preference scores.