ByteDance's VINCIE-3B Redefines Image Editing with AI
ByteDance Open-Sources Revolutionary Image Editing Model VINCIE-3B
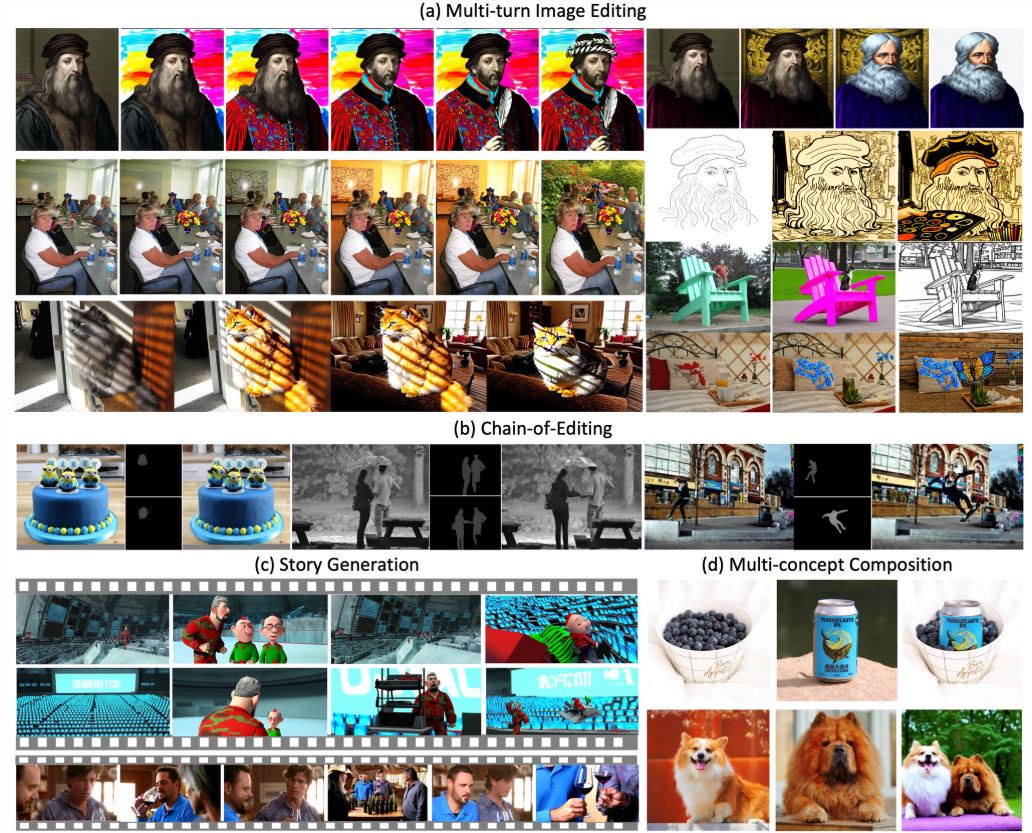
ByteDance has made waves in the AI community with the open-source release of VINCIE-3B, a groundbreaking 300 million parameter model that enables context-aware continuous image editing. This innovation represents a significant leap forward from traditional image editing approaches.
Technical Innovation
The model introduces several novel technical approaches:
- Video-driven training methodology that converts video frames into interleaved multimodal sequences (text + images)
- Block-Causal Diffusion Transformer architecture combining causal attention between blocks with bidirectional attention within blocks
- Triple agent task training enhancing dynamic scene understanding through next-frame prediction and segmentation tasks
- Hybrid input processing that handles both clean and noisy image conditions simultaneously
In benchmark tests, VINCIE-3B achieved state-of-the-art performance on KontextBench, particularly excelling in text following (94% accuracy) and character consistency (91% retention across edits). The model processes images approximately 8 times faster than comparable solutions.
Open Source Ecosystem
The complete package released on GitHub includes:
- Full model weights and architecture details
- Training data processing workflows
- A new multi-round image editing benchmark dataset
The Apache 2.0 license permits non-commercial use, with commercial applications requiring direct authorization from ByteDance.
Practical Applications
VINCIE-3B shines in several professional scenarios:
- Film post-production: Seamlessly moving characters between scenes while maintaining lighting consistency
- Marketing content creation: Automatically adapting product placements to various environments
- Game development: Rapid prototyping of character animations and scene variations
- Social media content: Transforming static images into dynamic sequences with simple text prompts
The model demonstrates particular strength in complex edits like "Move the girl in red from park to beach at sunset," maintaining impressive detail fidelity across transformations.
Current Limitations
While revolutionary, VINCIE-3B has some constraints:
- Optimal performance within 5 edit cycles
- Primary language support currently limited to English
- Potential copyright considerations for commercial use of outputs
The development team has indicated plans to address these limitations in future iterations.
Industry Impact
VINCIE-3B represents a paradigm shift from static to dynamic image editing. Its video-based training approach offers significant advantages over competitors like Black Forest Labs' FLUX.1Kontext or Bilibili's AniSora V3, particularly for applications requiring temporal consistency.
The open-source strategy positions ByteDance as a leader in AI-powered creative tools while potentially lowering barriers to entry across the creative industries.
Key Points:
- First context-aware image editor trained directly from video data
- Processes edits up to 8x faster than comparable models
- Maintains over 90% character consistency across multiple edits
- Apache 2.0 license enables broad non-commercial adoption
- Potential to revolutionize film, marketing, and game development workflows