ByteDance's Seeduplex Lets AI Listen and Talk Like Humans
ByteDance's New AI Breaks the Turn-Taking Barrier
Imagine trying to have a conversation where you can only speak when the other person stops completely. That's how most voice assistants work today - until now. ByteDance's Seed team just changed the game with Seeduplex, their new full-duplex voice model that launched April 9 on Douyin.
How Seeduplex Works Differently
Traditional voice AI uses half-duplex communication - like a walkie-talkie where only one person can talk at a time. Seeduplex shatters this limitation with its 'listen-and-speak simultaneously' framework. The results? Conversations that flow naturally, without those awkward pauses we've come to expect from digital assistants.
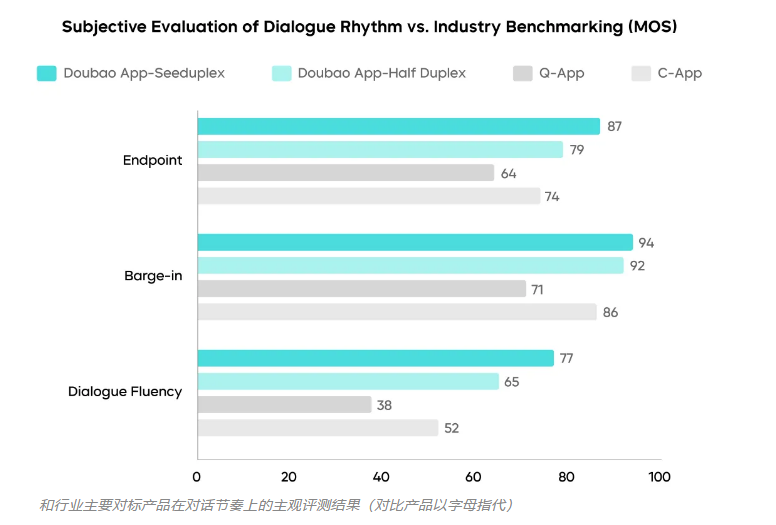
'We've essentially taught AI the rhythm of human conversation,' explains the Seed team. Their technology reduces response delays by 250 milliseconds and cuts interruptions by 40%, making interactions startlingly lifelike.
Cutting Through the Noise
Ever tried using voice commands in a crowded room? Most assistants fail miserably. Seeduplex tackles this through advanced audio processing that:
- Identifies primary speakers in group conversations
- Filters out background noise and overlapping speech
- Reduces false responses by 50% compared to previous models
The system even understands when you're pausing to think versus ending your statement - something even some humans struggle with!
Beyond Just Voice
ByteDance sees Seeduplex as just the beginning. With plans to integrate visual processing, future versions could analyze facial expressions and gestures while conversing. We're looking at assistants that don't just hear words, but understand context holistically.
Currently powering Douyin's voice features, the technology demonstrates how lab innovations can successfully scale to millions of users. While full-duplex isn't new conceptually, ByteDance's implementation marks a significant leap in making it work reliably in real-world conditions.
Key Points:
- Douyin now features simultaneous listening/speaking AI
- 40% fewer interruptions than traditional voice assistants
- Handles noisy environments and group conversations
- 250ms faster response times
- Evolutionary step toward multimodal AI assistants