ByteDance's Seed1.5-VL Model Sets New Benchmarks in Multimodal AI
At the recent Force Link AI Innovation Tour in Shanghai, ByteDance made waves with the official launch of Seed1.5-VL, its newest visual-language multimodal model. This compact yet powerful system has quickly become the talk of the AI community for its remarkable performance across multiple domains.

Breakthrough Capabilities The model demonstrates significant improvements over previous versions, particularly in visual positioning accuracy and processing speed. Its enhanced video understanding capabilities allow it to parse complex scenes with unprecedented precision, while new multimodal agent functions enable sophisticated task execution.
What makes Seed1.5-VL truly remarkable is its efficiency. With just 20 billion activation parameters, it matches the performance of much larger models like Gemini2.5Pro. Benchmark tests tell an impressive story - out of 60 public evaluations, Seed1.5-VL achieved state-of-the-art results in 38 tasks, particularly shining in video comprehension and visual reasoning challenges.
Cost-Effective Deployment For businesses considering implementation, the numbers look promising. The model offers input processing at 0.003 yuan per thousand tokens and output generation at 0.009 yuan per thousand tokens, making it one of the most budget-friendly options for enterprise-scale AI applications.
Developers can immediately access Seed1.5-VL's capabilities through Volcano Engine's API. By selecting the Doubao-1.5-thinking-vision-pro option, teams can rapidly integrate these advanced features into custom solutions ranging from AI visual assistants to next-generation surveillance systems.
In practical tests, Seed1.5-VL demonstrated remarkable real-world utility. When presented with retail shelf images, it could instantly identify products and calculate prices. More impressively, it solved complex civil service graphic reasoning problems that would challenge most human test-takers, identifying patterns and drawing logical conclusions within seconds.
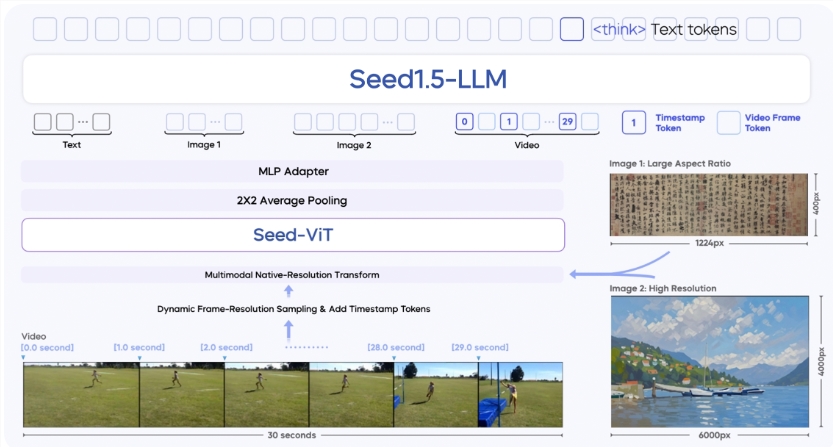
The model's architecture reveals the secret behind its capabilities:
- SeedViT visual encoding module for image processing
- Multilayer perceptron (MLP) adapter for visual feature projection
- Seed1.5-LLM language model based on MoE architecture
Trained on over 3 trillion tokens of multimodal data, Seed1.5-VL represents a significant leap forward in artificial intelligence's ability to understand and interpret our visually-rich world.
Key Points
- ByteDance's Seed1.5-VL achieves SOTA in 38 out of 60 benchmark tests
- The 20B-parameter model matches larger competitors' performance at lower cost
- Enhanced capabilities include superior video understanding and multimodal reasoning
- Available now through Volcano Engine API for enterprise integration
- Demonstrates practical utility in retail analytics and complex problem-solving