ByteDance Introduces QuaDMix to Optimize AI Training Data
ByteDance has unveiled QuaDMix, an innovative framework designed to revolutionize how Large Language Models (LLMs) are trained. This breakthrough addresses one of AI's most persistent challenges: balancing data quality with diversity during pre-training.
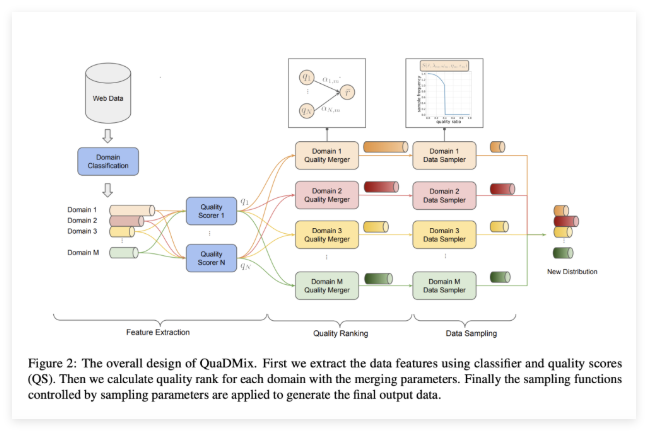
Traditional methods treat quality and diversity as separate objectives, often creating imbalanced datasets. High-quality collections frequently suffer from domain bias, while diverse datasets may include lower-quality content. QuaDMix's three-stage process eliminates this trade-off through:
- Feature extraction
- Documents receive domain labels and multiple quality scores
- Quality aggregation
- Scores are normalized and combined into comprehensive metrics
- Quality-diversity-aware sampling
- A sigmoid-based function selects optimal documents
The system doesn't just guess at optimal configurations. It trains thousands of surrogate models to predict performance outcomes, enabling precise tuning for specific applications. Tests on the RefinedWeb dataset proved its superiority, with QuaDMix achieving a 39.5% average score compared to traditional methods like random selection or Fineweb-edu.
What makes this approach groundbreaking? Rather than treating data selection as a preprocessing step, QuaDMix integrates it into the model optimization process. The framework automatically adjusts sampling parameters based on downstream task requirements, creating customized training sets for each application.
The implications are significant for AI developers. By optimizing both quality and diversity simultaneously, QuaDMix could reduce training costs while improving model performance. Early results show particular strength in specialized applications where domain balance proves critical.
Key Points
- QuaDMix combines quality scoring with domain-aware sampling in a unified framework
- The system outperforms traditional methods by 39.5% in benchmark tests
- Automated parameter optimization reduces manual tuning requirements
- Flexible architecture adapts to various downstream applications
- Potential to significantly reduce LLM training costs while improving accuracy