Breakthrough in Recurrent Models: 500 Steps Enable Ultra-Long Sequences
Breakthrough in Recurrent Models: 500 Steps Enable Ultra-Long Sequences
In the rapidly evolving field of deep learning, recurrent neural networks (RNNs) and Transformer models have long competed for dominance in sequence processing tasks. While Transformers excel in many areas, their limitations with ultra-long sequences—due to fixed context windows and escalating computational costs—have opened the door for RNNs to reclaim relevance.
The Challenge of Long Sequences
Transformers struggle with long-context tasks because their attention mechanisms scale quadratically with sequence length. This makes them inefficient for applications like genomic analysis or lengthy document processing. In contrast, linear recurrent models, such as Mamba, offer a more scalable alternative but historically underperformed on shorter sequences, limiting their adoption.
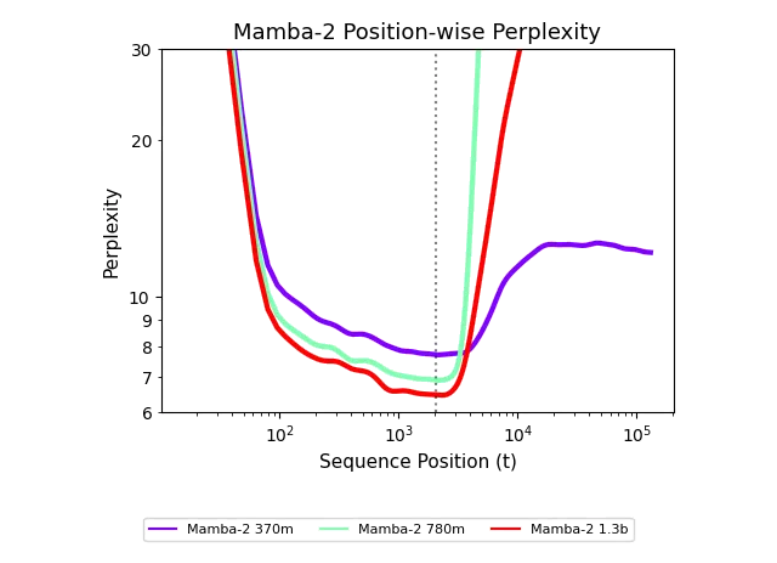
A Game-Changing Discovery
A team from Carnegie Mellon University and Cartesia AI has unveiled a groundbreaking approach to train recurrent models for length generalization. Their key insight? Just 500 steps of targeted training interventions can enable these models to handle sequences as long as 256k tokens—a feat previously unattainable.
The researchers introduced the "Unexplored States Hypothesis," which posits that recurrent models fail on long sequences because they encounter only a narrow range of states during training. To address this, they implemented:
- Random noise injection to broaden state exploration.
- Noise fitting techniques to stabilize learning.
- State transfer methods to preserve context across sequences.
Implications and Future Directions
This breakthrough not only proves that recurrent models lack no fundamental flaws but also opens new avenues for their use in large-scale data processing. The methods maintain state stability, ensuring reliable performance even in demanding applications like real-time language modeling or sensor data analysis.
The study’s findings were validated through rigorous experiments, demonstrating consistent improvements in model performance. This paves the way for further innovations in efficient sequence modeling, potentially reshaping industries reliant on long-context AI.
Key Points:
- 500 training steps enable RNNs to process sequences up to 256k tokens.
- The Unexplored States Hypothesis explains prior limitations and guides improvements.
- Techniques like noise injection and state transfer enhance generalization.
- Recurrent models now rival Transformers in scalability for long sequences.