Bilibili Open-Sources IndexTTS-2.0 with Emotional Control
Bilibili Releases Open-Source Text-to-Speech Model with Breakthrough Features
Bilibili's Index team has announced the full open-source release of IndexTTS-2.0, its advanced text-to-speech (TTS) system featuring controllable emotions and adjustable duration. This release marks a significant advancement in zero-shot TTS technology with practical applications across multiple industries.
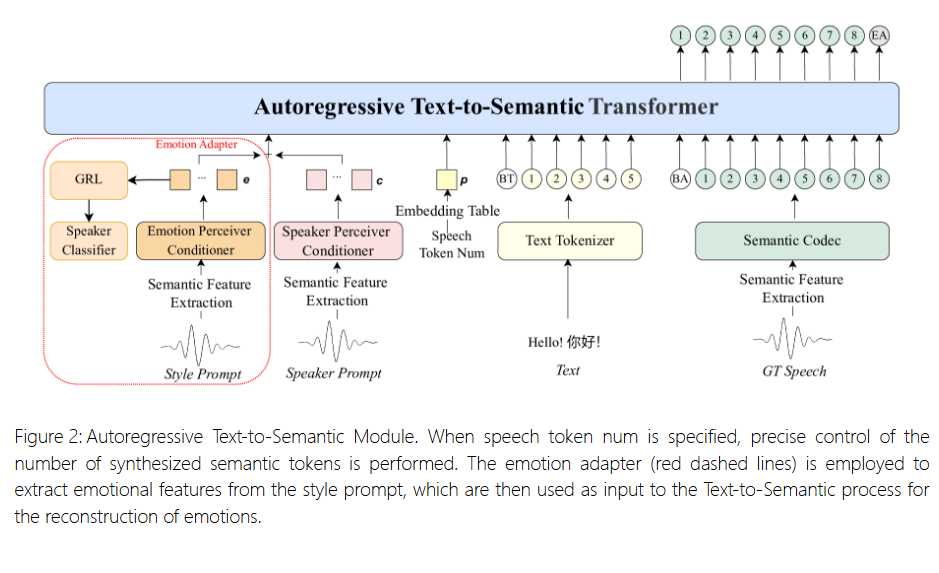
Technical Innovations
The system addresses two longstanding challenges in speech synthesis:
- Time Encoding Mechanism: First implementation in autoregressive TTS architecture that improves speech duration accuracy by 40%, enabling precise rhythm control
- Disentangled Emotion Modeling: Allows emotion adjustment through:
- Single audio reference
- Independent emotional reference audio
- Emotional vectors
- Text descriptions
"This flexibility revolutionizes synthetic speech expressiveness," noted the development team in their technical paper.
Global Applications
IndexTTS-2.0 demonstrates particular strength in:
- AI dubbing for cross-language video localization
- Audiobook production with emotional narration
- Podcast generation maintaining speaker style
The technology enables near "difference-free" localized experiences for content crossing language barriers, whether Chinese users consuming foreign media or international audiences accessing Chinese content.
Ecosystem Development
The complete package including:
- Research paper
- Full source code
- Model weights
- Online demo
has been released simultaneously on Hugging Face. The team plans ongoing optimizations and community collaboration to build multilingual voice technology ecosystems.
Key Points:
- ✅ Emotion control through multiple adjustment methods
- ⏱️ Precise duration control via innovative time encoding
- 🌐 Global content localization with natural voice preservation
- 🔓 Full open-source release including weights and demo