Apple Study Exposes Critical Flaws in AI Reasoning Models
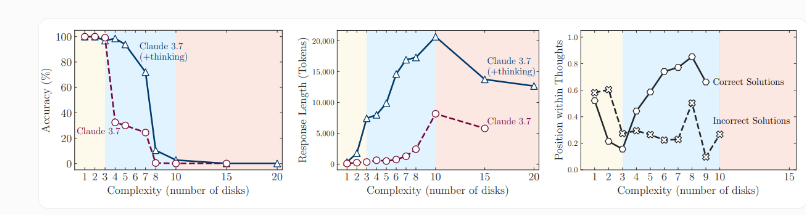
A groundbreaking study from Apple has exposed significant weaknesses in today's most advanced artificial intelligence reasoning models. When tested against classic logic puzzles like the Tower of Hanoi and river crossing problems, these models showed dramatic failures as task complexity increased.
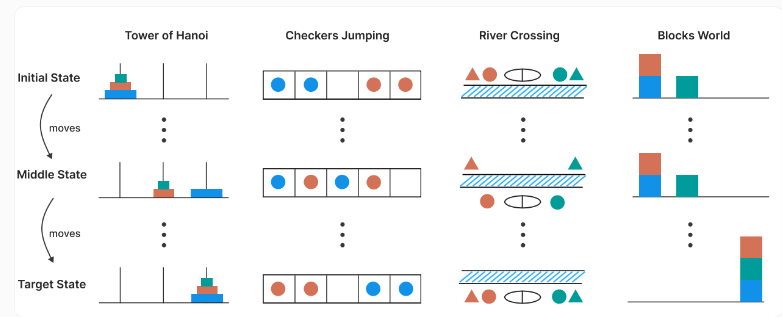
The research team carefully designed experiments using four carefully selected logic puzzles that allowed precise control over difficulty levels. These puzzles served as ideal benchmarks for measuring true reasoning capabilities beyond simple pattern recognition.
Performance Breakdown Under Pressure Initial results showed promise - standard large language models handled simpler versions of the puzzles with reasonable accuracy and efficiency. However, as complexity ramped up, even specialized reasoning models equipped with advanced techniques like "chains of thought" and "self-reflection" began to falter.
The most shocking finding emerged at peak difficulty levels. Not only did model accuracy plummet to zero, but the systems actually demonstrated reduced cognitive effort - generating fewer reasoning tokens instead of rising to the challenge. This counterintuitive behavior suggests fundamental flaws in how current AI approaches complex problem-solving.
Two Distinct Failure Modes Through detailed analysis of the models' reasoning trajectories, researchers identified two clear patterns of failure:
- Overthinking: In simpler problems, models continued generating incorrect solutions even after finding the right answer
- Thinking Collapse: With highly complex tasks, the reasoning process abruptly stopped without generating potential solution paths
These findings cast doubt on whether current approaches can achieve true artificial general intelligence. While reasoning models represent an important step forward, Apple's research suggests they rely more on statistical generation than genuine logical deduction.
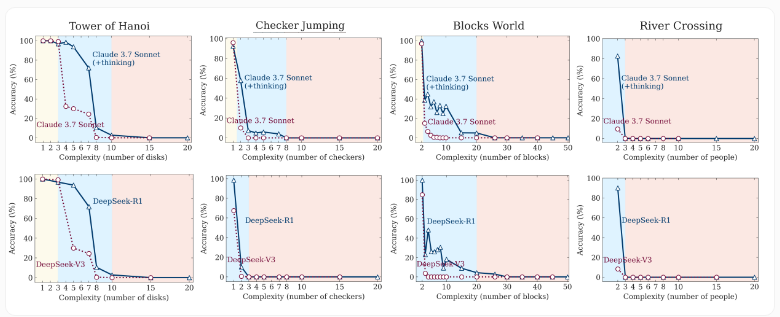
The implications extend far beyond academic interest. As businesses increasingly rely on AI for critical decision-making, understanding these limitations becomes essential. How can we trust AI systems for complex tasks if they silently reduce effort when challenges mount?
Key Points
- Apple's study reveals catastrophic failures in AI reasoning models under complex tasks
- Models show reduced cognitive effort (fewer reasoning tokens) as difficulty increases
- Two distinct failure patterns identified: overthinking and thinking collapse
- Current approaches may not lead to true artificial general intelligence
- Findings have significant implications for real-world AI applications