AliTongyi Open-Sources ThinkSound, a Breakthrough Audio Generation Model
Alibaba's ThinkSound Revolutionizes AI Audio Generation
Alibaba's Speech AI team has made a significant leap in artificial intelligence with the open-source release of ThinkSound, the world's first audio generation model supporting chain-of-thought reasoning. This breakthrough technology transforms how AI systems generate synchronized audio from visual inputs.
From Basic Dubbing to Structured Understanding
Traditional video-to-audio systems often struggle with maintaining spatiotemporal correlation between visual events and their corresponding sounds. ThinkSound addresses this limitation through its innovative three-stage reasoning process:
- Scene Analysis: The system first examines overall motion and scene semantics
- Sound Source Focus: It then identifies specific object sound source areas
- Interactive Editing: Finally, it allows real-time adjustments via natural language commands
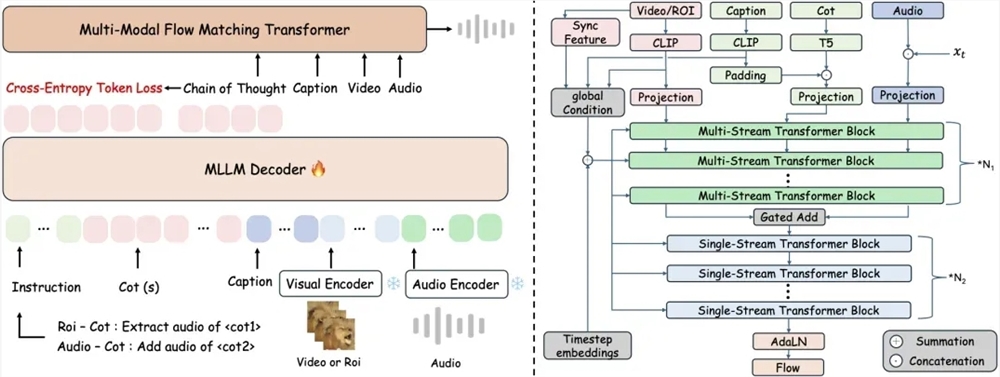
Advanced Training with AudioCoT Dataset
The research team developed the comprehensive AudioCoT multimodal dataset to train ThinkSound, featuring:
- 2,531.8 hours of high-quality audio samples
- Integrated content from VGGSound and AudioSet
- Multi-stage quality verification processes
- Specialized object-level and instruction-level samples
This robust training enables the model to handle complex instructions like "extract owl calls while avoiding wind interference."
Superior Performance Metrics
Experimental results demonstrate ThinkSound's advantages:
- 15% improvement over mainstream methods on VGGSound test set
- Outperforms Meta's comparable models on MovieGen Audio Bench test set The model's code and pre-trained weights are now freely available on:
- GitHub: https://github.com/FunAudioLLM/ThinkSound
- HuggingFace: https://huggingface.co/spaces/FunAudioLLM/ThinkSound
- ModelScope: https://www.modelscope.cn/studios/iic/ThinkSound
Future Applications and Industry Impact
The Alibaba team plans to expand ThinkSound's capabilities for:
- Complex acoustic environment understanding
- Game development and virtual reality applications Industry experts predict this technology will:
- Transform film/TV sound effects production
- Redefine human-computer interaction boundaries
- Accelerate innovation in the creator economy
Key Points:
- First audio generation model with chain-of-thought reasoning
- Three-stage process ensures precise sound-visual synchronization
- Trained on specialized 2,500+ hour AudioCoT dataset
- Outperforms competitors by significant margins
- Open-source availability promotes widespread adoption