Alibaba and Nankai University Unveil LLaVA-Scissor for Video Model Compression
Alibaba and Nankai University Launch LLaVA-Scissor for Efficient Video Processing
In a significant collaboration, Alibaba's Tongyi Lab and Nankai University's School of Computer Science have introduced LLaVA-Scissor, an innovative compression technology designed to optimize video large model processing. This development tackles critical challenges in video AI, particularly the inefficiencies caused by excessive token generation in traditional methods.
The Challenge of Video Model Processing
Traditional video models require individual frame encoding, leading to an exponential increase in tokens. While existing compression methods like FastV, VisionZip, and PLLaVA have shown promise in image processing, they fall short in video applications due to insufficient semantic coverage and temporal redundancy.
How LLaVA-Scissor Works
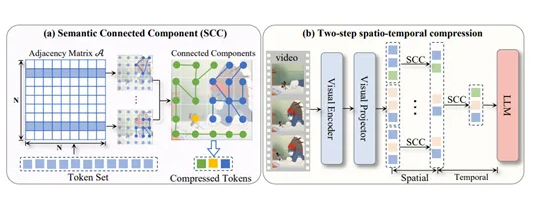
The new technology employs a graph theory-based algorithm called the SCC (Similarity Connected Components) method. This approach:
- Calculates token similarity
- Constructs a similarity graph
- Identifies connected components within the graph
Each component's tokens can then be represented by a single representative token, dramatically reducing the total count without losing critical information.
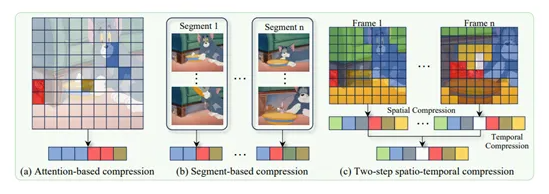
Two-Step Spatiotemporal Compression Strategy
LLaVA-Scissor implements a sophisticated dual-phase approach:
- Spatial compression: Identifies semantic regions within individual frames
- Temporal compression: Eliminates redundant information across multiple frames
This strategy ensures the final token set efficiently represents the entire video content.
Benchmark Performance Highlights
The technology has demonstrated exceptional results in various tests:
- Matches original model performance at 50% token retention
- Outperforms competitors at 35% and 10% retention rates
- Achieves 57.94% accuracy on EgoSchema dataset with 35% retention
The innovation shows particular strength in long video understanding tasks, addressing a critical industry need.
Future Implications
The development of LLaVA-Scissor represents more than just an efficiency improvement—it opens new possibilities for:
- Real-time video analysis applications
- Reduced computational resource requirements
- Enhanced scalability for large-scale video processing systems
The collaboration between industry and academia has yielded a solution that could reshape video AI development.
Key Points:
- 🚀 Efficiency breakthrough: Dramatically reduces token count while maintaining accuracy
- 🔬 Novel algorithm: SCC method provides intelligent semantic preservation
- 📈 Proven performance: Outperforms existing methods at low retention rates
- 🎯 Practical applications: Enables more scalable video processing solutions


