AI Models Fail New Benchmark: GPT-5 Scores Zero in Doctoral-Level Test
AI Models Stumble on Doctoral-Level Reasoning Test
In a striking revelation for artificial intelligence development, leading AI models including GPT-5 and Grok4 have scored zero points on a new benchmark designed to test advanced reasoning capabilities. The FormulaOne benchmark, developed by superintelligence research organization AAI, presents a sobering assessment of current AI limitations.
The FormulaOne Challenge
The benchmark consists of 220 novel graph-structured dynamic programming problems spanning complex mathematical domains including topology, geometry, and combinatorics. Problems range from moderate difficulty to research-level challenges comparable to doctoral examinations.
"These aren't just math problems," explained an AAI researcher who requested anonymity. "They require multi-step logical deduction and algorithmic innovation at levels we associate with advanced human cognition."
The test builds upon Courcelle's algorithmic meta-theorem, which states that for tree-like graphs, any logically definable problem can be solved using dynamic programming approaches. This requires sophisticated tree decomposition techniques - organizing graph vertices into overlapping sets arranged hierarchically.

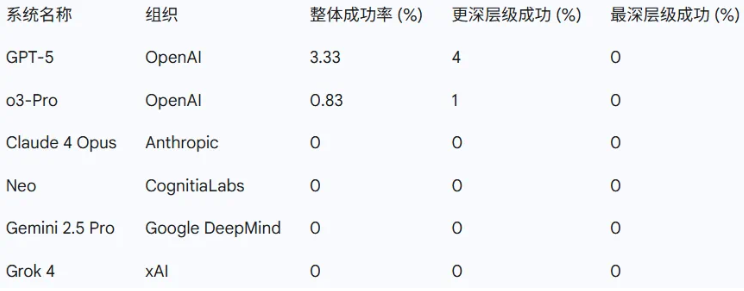
Performance Breakdown
Initial results show a stark contrast between surface-level and deep reasoning capabilities:
- Shallow Problems (50-70% success): Most models demonstrated basic comprehension
- Intermediate Challenges (1% success): Only GPT-5Pro solved four questions; others failed nearly completely
- Deep Problems (0% success): All models performed at chance level
"The shallow performance suggests these models have learned some problem patterns," noted Dr. Elena Torres, an AI researcher unaffiliated with the study. "But the complete failure on deep problems reveals they lack true understanding."
Implications for AI Development
The FormulaOne results have sparked intense debate within the AI community:
- Benchmark Validity: Some question whether the test fairly represents general intelligence
- Training Limitations: Others suggest current training methods may not develop genuine reasoning
- Human Comparison: Many advocate testing human PhD candidates for baseline comparison
The research team has made their evaluation framework publicly available on Hugging Face, inviting broader participation and scrutiny.
Key Points:
✅ Zero scores for top models on deepest FormulaOne challenges
✅ Benchmark tests doctoral-level reasoning through 220 dynamic programming problems
✅ Reveals stark gap between pattern recognition and true logical deduction
✅ Raises fundamental questions about current approaches to AI development