AI Models Compete in High-Stakes Math Exam: DouBao and YuanBao Triumph
In a remarkable demonstration of artificial intelligence capabilities, six major AI models recently competed in a simulated version of China's challenging high school entrance mathematics examination. The event, which pitted cutting-edge systems against one another, produced surprising results that highlight both the progress and limitations of current AI technology.

The competition featured prominent contenders including ByteDance's DouBao, Tencent's YuanBao, Alibaba's Tongyi, Baidu's WenXin X1Turbo, Shendu Qiusuo's DeepSeek, and OpenAI's o3. Each system tackled 14 objective questions from the 2025 New Curriculum Standard I Volume, totaling 73 possible points across multiple question formats.
To ensure fairness, organizers implemented strict conditions: no system prompts, no internet access, and only one attempt per model. The results revealed striking performance gaps among the competitors. DouBao and YuanBao shared top honors with identical scores of 68 points—just five points shy of perfection—demonstrating exceptional mathematical reasoning skills.
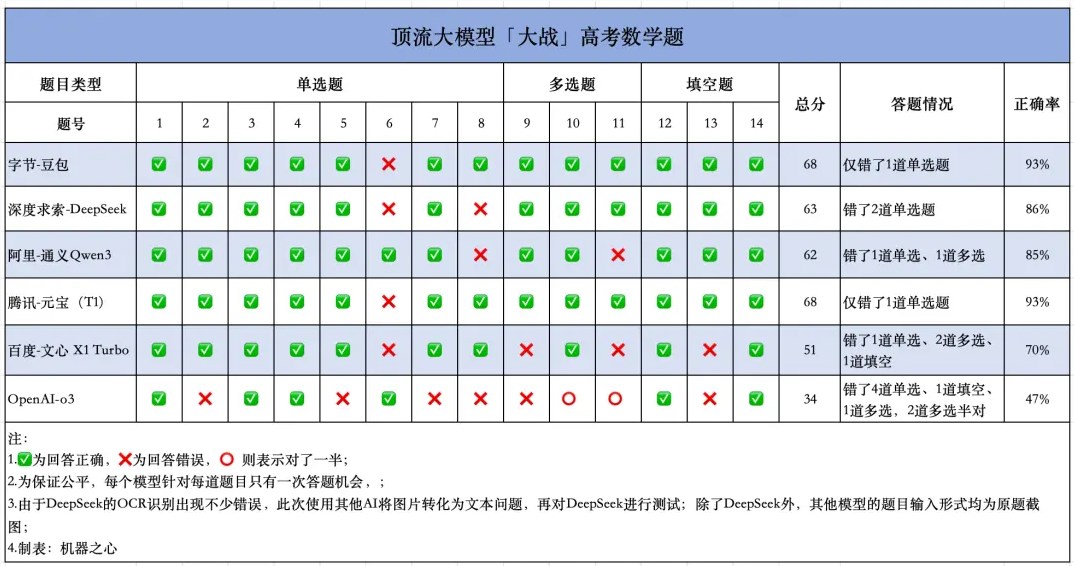
Other models showed mixed results. DeepSeek and Tongyi trailed the leaders with respectable but less impressive scores of 63 and 62 respectively. The performance gap widened dramatically with WenXin X1 and o3, particularly OpenAI's model which managed only 34 points—less than half the top score.
Drilling into specific question types reveals fascinating insights about each model's strengths. In single-choice questions (worth 35 points), DouBao, Tongyi and YuanBao achieved perfect scores while DeepSeek lost five points to two errors. O3 struggled significantly here, answering only half correctly for a meager 20-point showing.
Multiple-choice questions told a different story. DouBao, DeepSeek and YuanBao all demonstrated flawless performance—answering all three problems correctly—while Tongyi faltered under pressure despite its earlier speed advantage.
This competition serves as more than just an academic exercise. It provides concrete evidence of how rapidly AI reasoning capabilities are evolving while exposing persistent challenges. Compared to similar tests from previous years, today's models show marked improvement in formula application, logical processing, and attention to detail—though significant room for growth remains.
The results particularly highlight how localized training impacts performance. While international models like OpenAI's o3 excel in many contexts, they currently struggle with China's unique examination formats—a reminder that cultural context matters even in mathematics.
Key Points
- DouBao (ByteDance) and YuanBao (Tencent) tied for first place with 68/73 points
- OpenAI's o3 performed poorly (34 points), suggesting difficulty adapting to Chinese exam formats
- Models showed strongest performance in multiple-choice questions but varied widely in single-choice responses
- The test reveals significant progress in AI reasoning compared to previous years' benchmarks
- Localized training appears crucial for success in region-specific testing formats