Advancements in Video Object Tracking with Diffusion-Vas
Advancements in Video Object Tracking with Diffusion-Vas
In the realm of video analysis, understanding the persistence of objects is crucial for recognizing their existence, even when they are completely occluded. Traditional object segmentation techniques primarily focus on visible (modal) objects, often neglecting the handling of non-modal (both visible and invisible) objects.
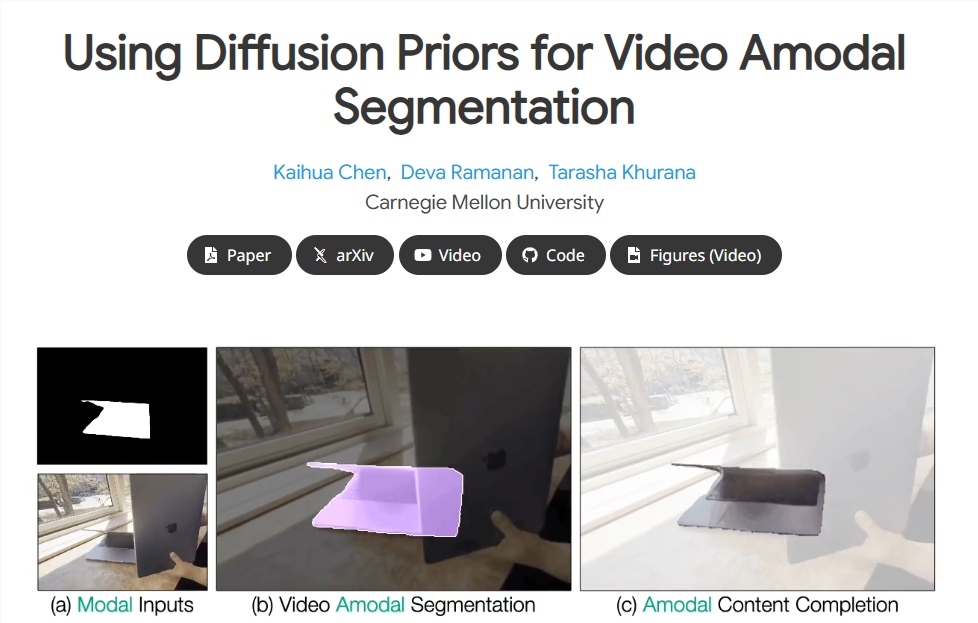
To tackle this significant limitation, researchers have proposed a two-stage method known as Diffusion-Vas. This innovative approach aims to enhance the performance of non-modal segmentation and content completion within videos. The method allows for the tracking of specific targets in video sequences, employing a diffusion model to fill in occluded areas.
Methodology
Stage One: Generating Non-Modal Masks
The initial phase of the Diffusion-Vas method involves the generation of non-modal masks for video objects. Researchers infer the occlusion of object boundaries by merging visible mask sequences with pseudo-depth maps. These maps are derived from monocular depth estimation of RGB video sequences. The objective of this stage is to identify which parts of the objects may be occluded, thereby extending the complete outline of the objects.
Stage Two: Content Completion
Following the creation of non-modal masks in the first stage, the second phase focuses on completing the content in occluded regions. The research team utilizes modal RGB content and implements conditional generative models to fill in these occluded areas, ultimately producing complete non-modal RGB content. This entire process is executed within a conditional latent diffusion framework supported by a 3D UNet backbone, ensuring high fidelity in the generated outputs.
Validation and Results
To evaluate the effectiveness of the Diffusion-Vas method, the research team conducted benchmarks on four distinct datasets. The results indicated a notable improvement in the accuracy of non-modal segmentation in occluded areas, with enhancements of up to 13% compared to various advanced methodologies. Notably, the Diffusion-Vas approach demonstrated remarkable robustness in complex scenes, effectively managing strong camera motion and frequent complete occlusions.
This research not only improves the accuracy of video analysis but also offers a new perspective on understanding the existence of objects within intricate settings. The potential applications for this technology are vast, with future implementations expected in areas such as autonomous driving and surveillance video analysis.
For more details on the project, visit Diffusion-Vas Project.
Key Points
- The research introduces a new method for non-modal segmentation and content completion in videos using diffusion priors.
- The method is divided into two stages: first, generating non-modal masks; second, completing the content of occluded areas.
- Benchmark tests demonstrate significant improvements in the accuracy of non-modal segmentation, particularly in complex scenes.