Yuan3.0Flash:改变游戏规则的开源AI新势力
AI竞技场的新晋强者
YuanLab.ai团队通过最新发布的Yuan3.0Flash掷下战书——这款开源多模态基础模型正在AI界引发轰动。其独特之处在于:这不仅是又一个大型语言模型,更是精心设计的兼顾性能与效率的解决方案。
更智能而非更费力
Yuan3.0Flash核心拥有400亿参数,但其精妙之处在于采用稀疏混合专家(MoE)架构——推理时仅激活约37亿参数。这种创新方法意味着您能获得顶级性能,却不必承受大型模型常见的能耗问题。
"'更低算力,更高智能'并非营销话术",YuanLab.ai的陈博士解释道:"我们构建的系统知道何时全力以赴,何时保存资源"。
技术揭秘
其魔力源自三大核心组件:
- 视觉编码器:将图像转换为标记
- 语言主干网络:搭载局部过滤增强注意力机制(LFA)
- 多模态对齐模块:实现系统间无缝协作
这种架构不仅停留在理论层面——它正在企业场景中产出令人瞩目的实际成果。
以彼之道还施彼身
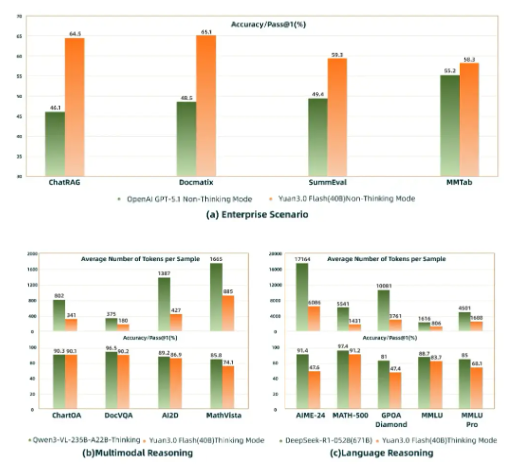
在直接对比中,Yuan3.0Flash已在多项关键商业应用中超越GPT-5.1:
- ChatRAG(检索增强生成)
- Docmatix(多模态文档理解)
- MMTab(表格理解)
该模型面对更大体量竞争者同样不落下风——仅需消耗对手25%-50%的计算资源,就能达到高达6710亿参数模型的精度水平。
企业级价值体现
对寻求AI解决方案的企业而言,这些性能提升直接转化为成本节约。"我们看到企业在保持或提升输出质量的同时,推理成本降低了50%-75%",一位金融业早期使用者指出。
Yuan3.0Flash的开源特性更添魅力——允许各组织根据需求定制模型而无需担心供应商锁定。
未来蓝图
YuanLab团队并未止步于此。他们已宣布将推出参数规模高达1万亿的Pro和Ultra版本,为专业应用场景提供更强能力。
随着AI持续快速发展,像Yuan3.0Flash这样的解决方案证明:更大未必更好——通过精巧架构与深思熟虑的设计,无需超级计算机级别的资源也能实现超常成果。
核心亮点:
- 开放创新:完整提供权重与技术文档供社区开发
- 效率标杆:MoE架构以适中算力需求交付卓越性能
- 企业就绪:已在关键商业应用中超越GPT-5.1
- 成本优势:较之大模型显著降低运营支出
- 面向未来:规划中的扩展版本将应对更复杂用例