你的手机变得更智能了:谷歌Gemini AI现已能处理真实任务
谷歌Gemini AI学会像你一样使用手机
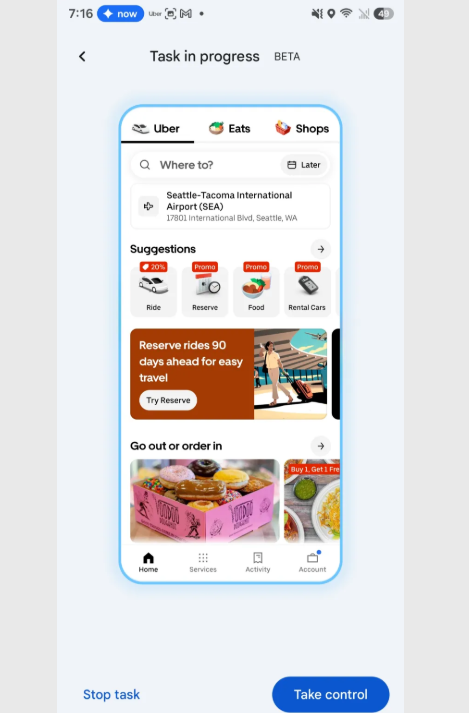
想象一下告诉你的手机“点我常喝的咖啡”,然后看着它像你一样操作星巴克应用——滚动菜单、选择选项,并在支付前停下等待你的确认。随着谷歌推出基于Gemini的任务自动化测试版,这一科幻场景本周已成为现实。
工作原理:数字模仿
与依赖后台API的传统应用集成不同,Gemini的新技巧涉及更非凡的能力:它实际上是通过视觉学习使用应用。这款AI能够:
- 独立打开应用 当收到语音指令时
- 导航界面 通过模拟点击和滑动操作
- 处理多步骤流程 比如比较不同服务的配送时间
- 策略性暂停 在关键决策点(如支付页面)
“起初这有点诡异,”早期测试者Marco Chen承认,“你看着手机自己滚动菜单,在选项前犹豫的样子就像人类一样。”
安全第一:内置人工监督
谷歌已实施多重保障措施:
- 实时监控:每个操作都会显示在专用窗口中,用户可以即时干预。
- 强制确认:未经用户明确批准,不会完成任何交易。
- 控制性发布:目前仅限于外卖和打车应用。
该系统尚不完美——测试者报告在处理复杂菜单结构或弹窗广告时偶尔会出现问题。但其潜力巨大。
为何这是革命性的改变
这种方法绕过了特殊开发者集成的需求,意味着Gemini最终可能适用于几乎所有应用:
- 没有API接入的小型企业同样受益
- 地区性应用无需额外开发即可获得功能
- 用户保持对其数字体验的控制权
其影响不仅限于便利性——想象帮助年长亲属自动支付账单或协助残障人士更轻松地使用数字服务。
目前测试版支持特定安卓设备上的英语指令,预计今年晚些时候将扩大推广范围。
关键要点:
- 视觉自动化:Gemini通过界面而非API与应用交互
- 人工监督:关键步骤始终需要手动确认
- 广泛潜力:最终可能适用于几乎所有移动应用
- 当前限制:仍难以应对某些视觉元素和弹窗