清华与腾讯联手取得AI突破:MoE推理速度提升4.1倍
中国研究团队在AI效率挑战赛中力压全球竞争对手
清华大学存储实验室与腾讯MegEngine AI基础架构团队的研究人员展现了非凡的技术实力,在MLSys2026 MoE推理挑战赛中拔得头筹。他们优化混合专家模型的突破性工作为AI效率设立了新标准。

突破瓶颈
面对在专用神经处理器(NPU)上运行万亿参数MoE架构的巨大挑战,联合团队开发了全面的优化策略。"我们意识到必须重新思考推理管道的每个环节,"清华首席研究员陈亮博士解释道,"传统方法根本无法应对这些超大规模模型。"
他们的解决方案?一个从多角度解决问题的组合策略:
- E-Shard策略:按专家模块划分计算任务的智能分区方法
- PSUM 3D张量读取:优化数据在处理管道中的流动方式
- GEMV路径创新:通过将输出分散到多个Banks实现并行处理
- 标量引擎利用:显著减少初始数据传输延迟
"真正的突破点在于,"腾讯工程负责人张伟指出,"我们从算子层面解决了数据移动与激活传递的根本效率问题。"
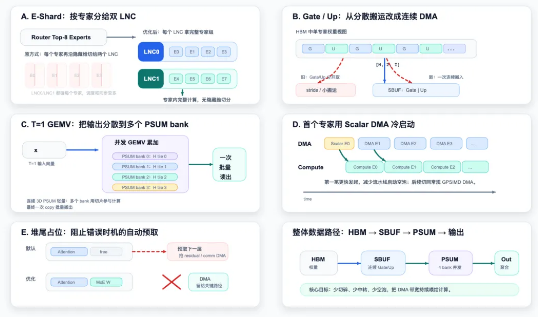
图3:团队开发的MoE优化架构,展示了专家分区、数据传输与并行处理的集成方案。
秘密武器"骑士"
团队的杀手锏是名为"骑士"的自动推理优化器,它采用基于智能体的方法探索优化可能性。这个精妙的系统能生成提案、实施代码修改,并持续循环迭代改进。
成效不言自明:
- 端到端推理时间从14.91秒锐减至3.56秒
- 单步解码延迟降低超半数(从12.63ms降至5.45ms)
- 权重加载时的DMA引擎利用率提升至约80%
"骑士帮助我们发现了可能被忽略的优化路径,"陈博士坦言,"就像拥有一个永不休息的额外团队成员。"
超越顶尖
考虑到参赛者包括斯坦福、MIT等研究强校,中国团队的成就更显非凡。"这不仅关乎原始性能,"张伟强调,"我们聚焦于创造可实际落地的解决方案。"
业界专家已开始关注。"这项工作为高效部署超大规模MoE模型提供了蓝图,"剑桥大学AI研究员Emma Johnson评价道,"4.1倍的提升不仅令人印象深刻——对于需要万亿参数模型实时响应的应用而言,这可能是颠覆性的。"
关键要点
- 创纪录表现:NPU硬件上MoE模型推理速度提升4.1倍
- 创新技术:E-Shard分区、PSUM 3D张量处理、GEMV路径优化
- 自动化优势:"骑士"优化器扩展了潜在改进的搜索空间
- 实际影响:解决了超大规模AI模型实际部署的挑战
- 全球认可:在MLSys2026上超越国际顶尖高校团队