通义千问发布Qwen3-ASR-Flash语音识别模型,树立新标杆
通义千问Qwen3-ASR-Flash为语音识别设立新标准
在语音转文字技术的重大进展中,通义千问正式发布了其最新自动语音识别(ASR)模型Qwen3-ASR-Flash。基于Qwen3基础模型构建,这项创新在语音AI应用的准确性和功能性上实现了重大飞跃。
突破性性能指标
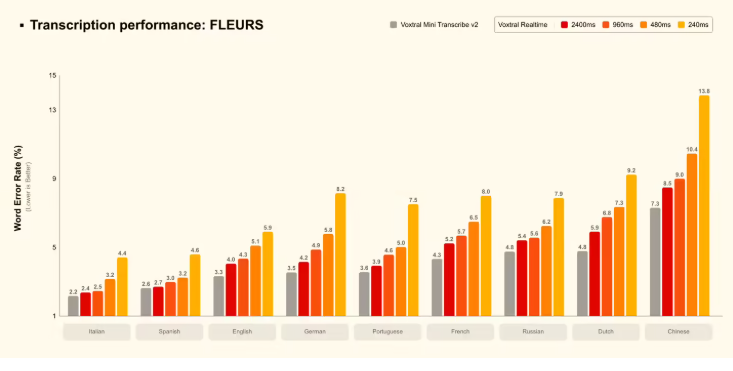
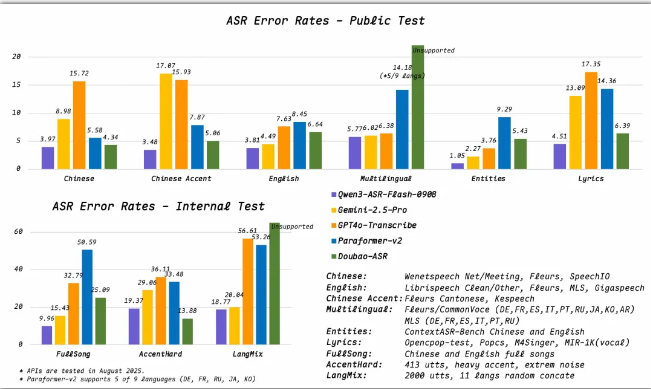
新模型在多项基准测试中展现出卓越能力:
- 在歌声识别测试中达到低于8%的错误率
- 对长复杂句子保持高准确度
- 有效处理单次发音中的语言切换
- 以惊人精度过滤背景噪音和非语音片段
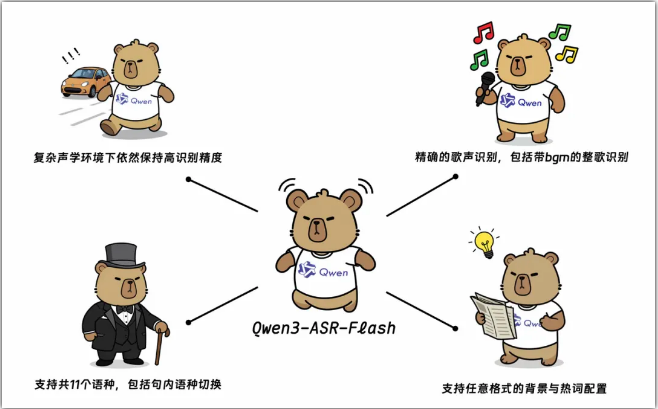
多语言与方言支持
Qwen3-ASR-Flash凭借其广泛的语言能力脱颖而出:
- 支持包括英语、普通话、法语、德语和日语在内的11种主要语言
- 可识别如四川话和粤语等地区变体
- 适应语言群体内的不同口音(如英式与美式英语)
该模型的架构使其能在多样化的语言环境中保持性能一致性。
高级语境理解能力
除基本转录外,该模型还提供:
- 可定制识别:用户可提供文本上下文以提升实体识别率
- 命名实体匹配:智能识别关键术语和专有名词
- 自适应格式化:根据提供的上下文线索调整输出格式
这些特性使Qwen3-ASR-Flash特别适合需要精确术语捕捉的专业领域。
技术实现与可用性
该模型的训练基于:
- 海量多模态数据集
- 数千万小时ASR专项数据
公司已通过多个平台开放技术访问:
- ModelScope
- HuggingFace
- 阿里云百炼API
未来发展路线图
通义千问计划持续改进包括:
- 提升准确度指标
- 增加语言支持
- 开发新功能
- 专业领域适配
公司旨在将Qwen3-ASR-Flash打造为企业级语音识别应用的标杆解决方案。
关键亮点:
- 以<8%的歌声识别错误率实现行业领先精度
- 支持包含主要方言口音的11种语言
- 具备针对专业用例的可定制语境适应功能
- 在复杂声学环境中保持稳健性
- 通过多个云平台提供即时部署方案