腾讯公布低成本AI优化方法
腾讯在高效能AI优化领域的突破
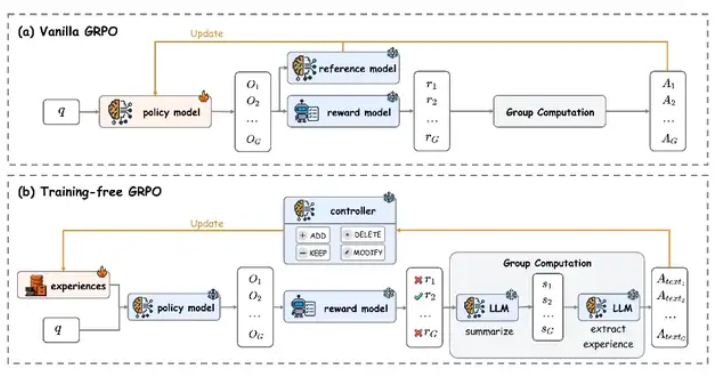
腾讯AI实验室开发了Training-Free GRPO(基于梯度的策略优化),这是一种无需传统参数微调即可优化大语言模型的革命性方法。这项创新在显著降低计算成本的同时,提供了可比的性能提升。
Training-Free GRPO工作原理
该技术将经验知识转化为标记级先验信息,使模型能在不改变核心参数的情况下实现改进。通过动态维护外部经验知识库,该方法在保持主模型架构的同时增强了能力。
性能提升
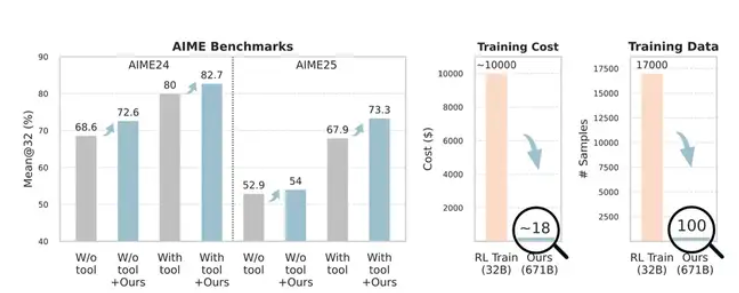
在DeepSeek-V3.1-Terminus上的测试显示显著进步:
- 数学推理:AIME24准确率从80%提升至82.7%,AIME25从67.9%提升至73.3%
- 网络搜索任务:Pass@1指标从63.2%提高至67.8%
该方法仅使用100个跨领域训练样本就取得了这些成果,而传统方法通常需要数千个样本。
成本对比
财务影响令人震惊:
- 传统微调:约70,000元人民币
- Training-Free GRPO:约120元人民币
节省主要来自避免梯度反向传播和参数更新等计算密集型操作。
对AI发展的意义
这一突破可能使高级AI优化技术更普及:
- 使资源有限的小型组织也能提升模型性能
- 保持模型跨领域的泛化能力
- 为高效的持续学习系统开辟新可能性
研究团队承认需要在数学推理和信息检索之外更广泛的任务类别中进行进一步测试。
论文参考: Training-Free GRPO on arXiv
关键要点:
- 以<0.2%的成本实现与传统微调相似的结果
- 通过更新外部知识库而非模型参数实现优化
- 在数学和搜索任务中展示出有效性
- 对资源受限的组织尤其有价值