腾讯在OpenClaw数据抓取争议中为数据使用辩护
腾讯因AI数据抓取行为面临强烈反对
OpenClaw开发者Peter Steinberger公开指责腾讯未经授权从其ClawHub平台抓取数据后,AI社区一片哗然。这场争议揭示了企业创新与开源伦理之间的微妙平衡。
指控内容
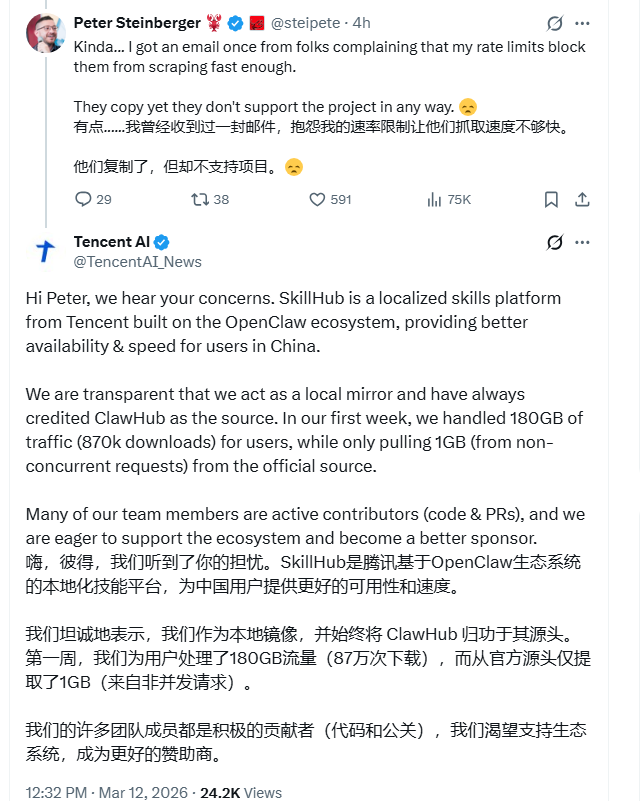
Steinberger在社交媒体平台X上发表了令人震惊的声明:“腾讯复制了我们整个技能数据库来构建他们的SkillHub平台,”他写道。“他们既没有征求许可,也没有提供支持——只是拿走了他们想要的东西。”更令人不安的是,Steinberger分享了电子邮件,显示腾讯员工抱怨ClawHub的访问限制影响了他们的抓取效率。
腾讯的回应
这家中国科技巨头迅速通过其官方AI账号进行了反击。他们的辩护基于三个关键点:
- SkillHub是作为本地化镜像设计的,旨在提高中国用户的访问速度
- 他们的技术数据显示他们将ClawHub的带宽压力降低了惊人的99.4%
- 团队成员积极为OpenClaw生态系统做出贡献
“仅在第一个星期,”一位腾讯发言人指出,“我们就在本地处理了180GB的流量,而从ClawHub只拉取了1GB。”
冲突的核心
尽管腾讯将SkillHub描述为一项造福中国用户的服务,但Steinberger的看法截然不同。“这不是关于带宽的问题,”他在后续帖子中反驳道。“这是关于尊重开源许可证和基本开发者权利的问题。”
这场争议反映了随着AI应用加速而出现的更广泛紧张局势:
- 企业竞相实施新技术
- 独立开发者寻求认可和公平补偿
- 关于什么是开源材料的道德使用的疑问
展望未来
腾讯表示愿意通过赞助协议正式建立合作关系。但Steinberger坚持认为任何合作都必须从适当的归属和相互协议开始——而不是单方面行动。
这一结果可能为科技巨头未来如何与开源社区互动设定重要先例。
关键点:
- OpenClaw开发者指控腾讯未经授权抓取数据
- 腾讯称其镜像网站将原始流量减少了99%
- 辩论凸显了企业与开源利益之间日益增长的紧张关系
- 双方都表示愿意在未来按照适当条款进行合作