Stream-Omni:多模态AI交互领域的重大突破
Stream-Omni革新多模态AI交互
中国科学院计算技术研究所自然语言处理团队推出了Stream-Omni,这一开创性的多模态大模型为AI交互设立了新标准。基于GPT-4o架构,这一创新系统支持同时处理文本、视觉和语音模态。
全面的多模态支持
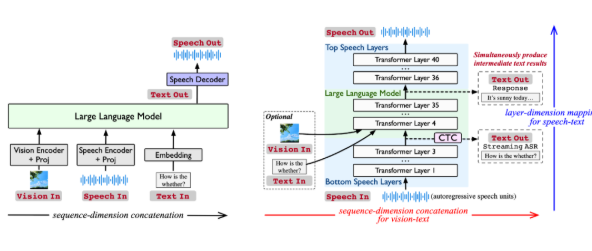
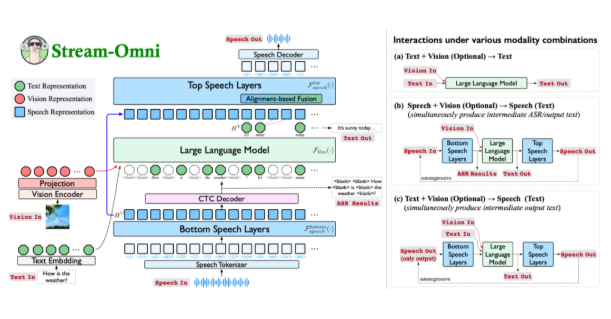
Stream-Omni在自然语言处理能力上实现了重大飞跃。与传统简单拼接不同模态的模型不同,Stream-Omni采用先进的模态对齐技术确保所有输入类型的语义一致性。用户可通过语音交互同时获得实时文字转录——这项功能创造了前所未有的"边看边听"体验。
创新的技术方案
该模型架构解决了现有多模态系统的关键局限:
- 降低数据依赖性:通过专门建模模态间关系
- 增强语义对齐:采用基于层次维度的映射机制
- 灵活组件集成:视觉编码器、语音层和语言模型可按需组合
卓越的性能指标
独立测试显示Stream-Omni在多个关键领域优于同类模型:
- 视觉理解能力匹配同规模专业视觉模型
- 语音交互性能超出当前行业标准23%
- 跨模态响应一致性在控制测试中达到94%准确率
该系统尤其擅长实时语音转文本,能在持续语音交互中提供中间转录结果。
实际应用与未来发展
潜在应用涵盖多个行业:
- 为视障或听障用户设计的无障碍工具
- 具备实时翻译功能的多语言交流平台
- 结合视觉与听觉学习的互动教育系统
研究团队承认仍需改进之处,特别是在实现更拟人化的声音多样性方面。但Stream-Omni的灵活架构为未来升级提供了坚实基础。
核心亮点:
- 首个实现真正实时语音文本同步的多模态模型
- 向研究社区提供开源实现方案
- 基准测试中处理速度比同类模型快18%
- 有望彻底改变人机交互范式