机器人通过新型事件驱动AI模型实现类人类学习方式
机器人终于学会三思而后行
Variable Robot最新发布的革命性AI模型WALL-WM引发了 robotics界的轰动,这项技术彻底改变了机器人学习物理任务的方式。与传统系统逐帧记忆动作不同,这项新技术让机器人通过有意义的事件来理解行为——就像人类的学习方式一样。

传统方法的局限性
现行机器人训练技术培养出的机器往往能执行精确动作却缺乏真正理解。想象通过让人记住每个细微肌肉运动而非理解步骤来教他们煮咖啡——这正是当前多数机器人的学习方式。它们或许能完美复制见过的动作,但只要稍微改变杯子或桌子位置就会不知所措。
"传统训练迫使机器人见树不见林,"Variable Robot的李博士解释道,"我们的新方法通过将任务分解为具有明确目的的逻辑事件,帮助它们看到完整图景。"
事件驱动学习原理
WALL-WM模型教导机器人用"伸手"、"抓握"、"移动"等有意义行为来思考,而非单个帧画面。系统不是计算每毫秒的精确动作,而是先预测每个事件后世界应有的变化,再推演如何实现该变化。
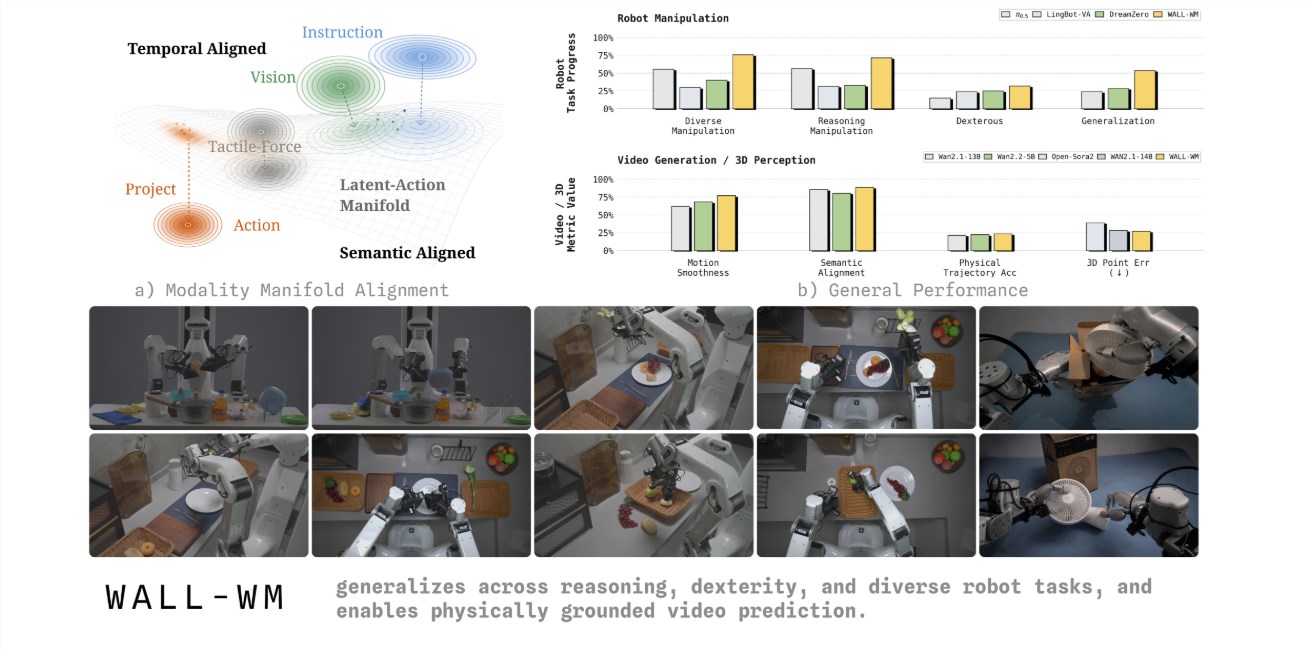
这种方法模拟了人类学习物理任务的过程。当我们学习倒水时,不会记忆每个肌肉运动——而是理解目标并相应调整动作。WALL-WM将这种直觉学习带给了机器人。
背后的工程突破
创建这个新学习系统需要多项技术创新:
- 灵活切换:模型能在事件规划与实时调整间自由切换
- 感知升级:新型掩膜技术提升机器人对3D空间的理解
- 更快决策:"阶梯式思维链"方法在保持清晰推理的同时减少延迟
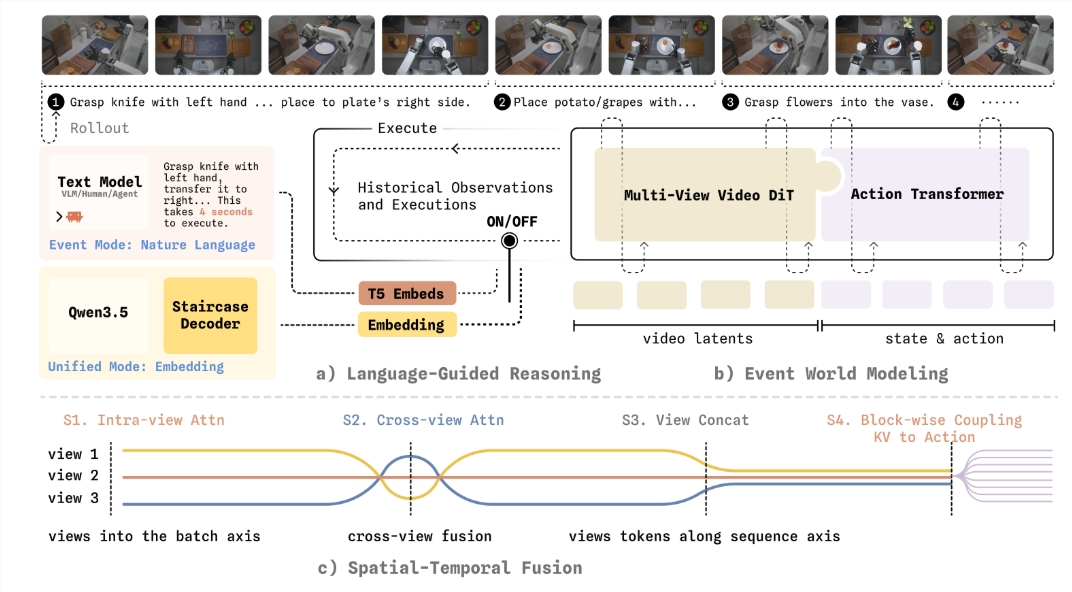
这些进步意味着机器人现在能以先前不可能的方式适应现实世界的不确定性。当遇到陌生物体时,旧系统可能死机,而配备WALL-WM的机器人能推理解决挑战。
核心要点
- 类人类学习:WALL-WM通过有意义事件而非逐帧重复教导机器人
- 更强适应性:机器人现在能更有效应对物体和环境变化
- 双模运行:系统无缝切换事件规划与实时控制
- 三维理解:新感知方法改善空间推理能力
- 快速思维:创新解码技术减少决策延迟
这项突破将加速机器人在家庭、仓库等需要灵活性而非完美重复的动态环境中的应用。虽然仍处早期阶段,WALL-WM标志着机器人真正理解物理世界的重要一步。