机器人像人类一样学习:新型AI模型通过事件而非帧来理解任务
机器人开始用事件思考,而非单纯动作
机器人领域因WALL-WM的推出迎来重大飞跃,这个新的人工智能模型像人类一样学习任务——通过理解有意义的事件,而非记忆无数单独动作。由Variable Robot团队开发的这项创新,可能最终帮助机器人突破目前在执行复杂任务方面的限制。

当前机器人学习的问题
迄今为止,大多数视觉-语言-动作(VLA)模型通过逐帧分析来运作——就像逐帧观看电影而非理解整个故事。这种方法迫使机器人通过无休止重复微小物理动作来学习,常常忽略了它们实际要完成任务的全局图景。
"想象一下通过让人记住每个微小手部动作来教他们煮咖啡,"熟悉该项目的一位研究员解释道。"如果你换了咖啡杯或移动了糖碗,他们精心记忆的动作就变得毫无用处。这本质上就是当今机器人的学习方式——也是它们经常难以应对环境中简单变化的原因。"
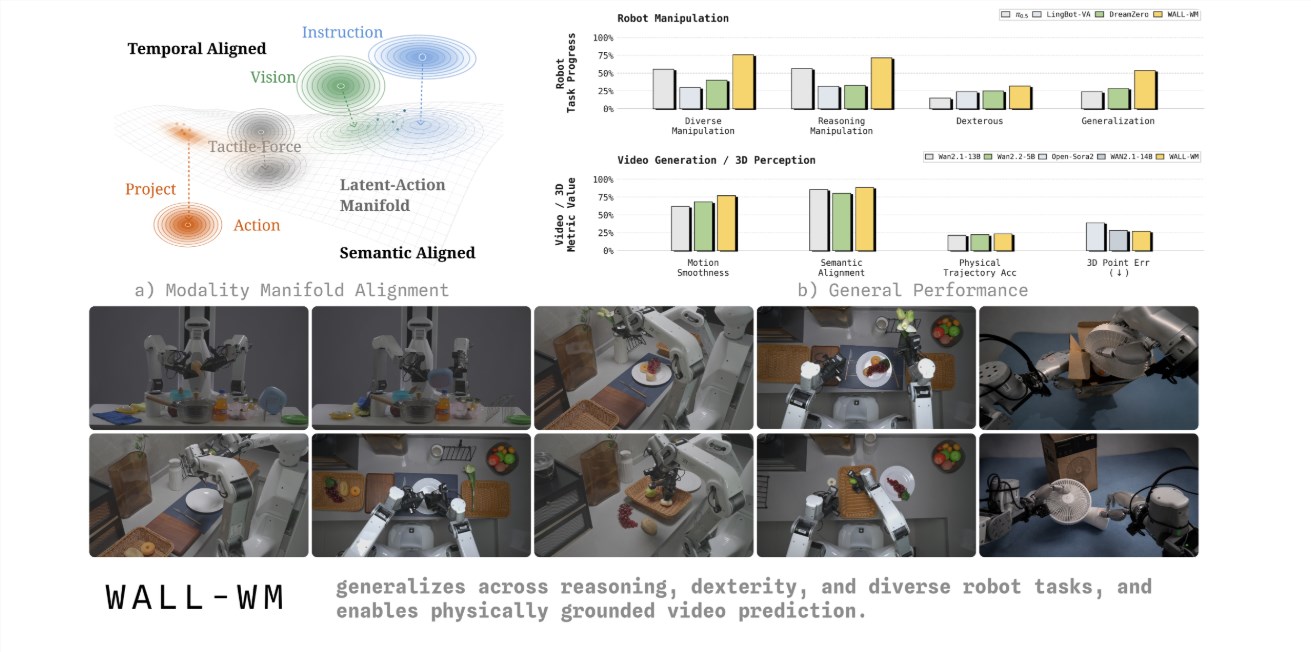
WALL-WM如何改变游戏规则
新模型采用截然不同的方法,将任务分解为具有明确目的的有意义事件——"伸手拿杯子"、"握住把手"、"倒液体"——而非关注动作的单独帧。这就像记住舞步与理解自己在跳华尔兹的区别。
以下是它在实践中的工作方式:
- 机器人首先模拟下一个事件将如何改变其环境
- 然后将这个预计变化转化为精确的手臂动作
- 系统根据实际结果持续更新其理解
这种基于事件的学习带来多个优势。机器人能更好地适应环境变化,在相似任务间转移技能,甚至能在问题发生前预测潜在问题。早期测试在厨房环境中显示出特别有前景的结果,因为那里的物品经常改变位置和方向。
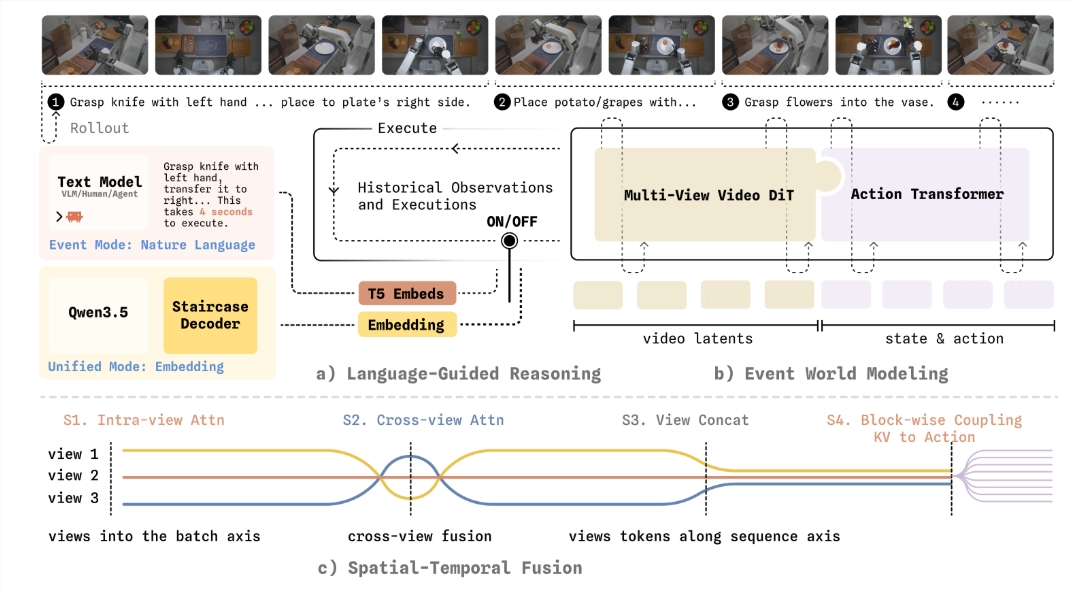
突破背后的工程技术
要使这种理论方法在物理世界中奏效,需要一些巧妙的工程解决方案。Variable团队开发了一个系统,可以实时在基于事件的规划和调整之间切换,就像人类可能在规划路线与驾驶时做出小幅转向修正之间交替一样。
他们还解决了几个技术挑战:
- 防止系统在学习动作时丢失有价值的视觉信息
- 提升多摄像头视角下的3D空间感知
- 通过"阶梯式思维链解码"减少决策延迟
结果是一个不仅能遵循预编程动作,而且真正理解自己试图完成什么的机器人——这是迈向能在我们不可预测的人类世界中可靠运作的真正智能机器的关键一步。
关键点:
- 基于事件的学习: WALL-WM将任务理解为有意义事件的序列而非单独动作
- 更好的适应性: 机器人能更有效地处理环境变化
- 现实世界就绪: 系统包含规划和实时调整的机制
- 技术创新: 包括3D感知和决策速度的解决方案
- 类人学习: 反映人类理解和执行复杂任务的方式