Pangram在准确性和成本上超越AI检测工具
Pangram以无与伦比的准确性引领AI文本检测
芝加哥大学的一项全面研究将Pangram确定为目前最可靠且最具成本效益的AI文本检测工具。该研究比较了六个文本类别和四种主要语言模型下的多种检测系统。
方法论:严格的测试框架
研究团队构建了一个包含1,992篇人工撰写文本的数据集,涵盖:
- 亚马逊产品评论
- 博客文章
- 新闻稿件
- 小说节选
- 餐厅评论
- 简历
这些文本与来自GPT-4.1、Claude Opus4、Claude Sonnet4和Gemini 2.0 Flash的AI生成内容进行了配对比较。性能通过以下指标衡量:
- 误报率(FPR):人工文本被误判为AI生成
- 漏报率(FNR):未被检测出的AI生成内容
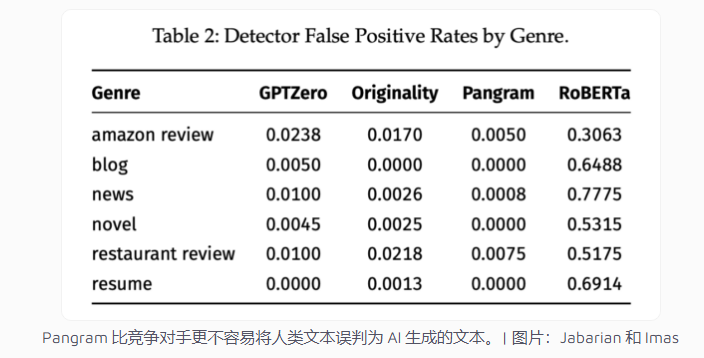
性能分析:Pangram占据主导地位
研究结果显示Pangram实现了:
- 对中长文本的近乎完美检测(0%错误率)
- 即使在短样本中也保持极低错误率(<0.01)
- 在所有测试的四种AI模型中表现一致
基于RoBERTa的开源检测器表现最差,错误地将30%-69%的人工写作标记为机器生成。
模型特异性检测差异
研究揭示了不同检测器处理各类AI系统输出的显著差异:
| 检测器 | 优势 | 劣势 |
|---|
研究指出,虽然所有检测器在小说等长篇内容上表现良好,但Pangram即使在简短的餐厅评论中也能保持卓越的准确性。
反规避能力测试
团队使用旨在绕过检测的工具StealthGPT评估了各系统:
- Pangram的性能保持稳定(<5%波动)
竞争对手显示出20%-40%的准确率下降
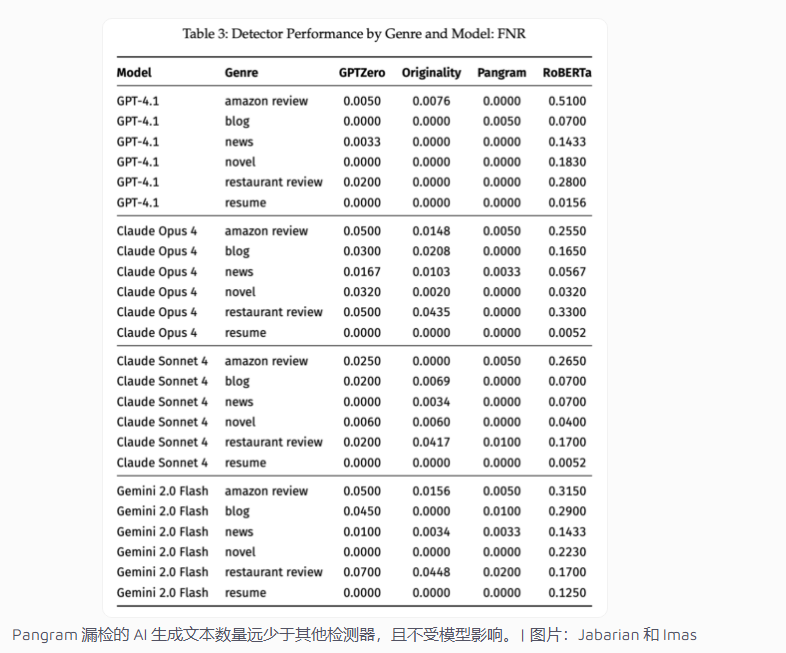
经济优势显现
成本分析显示:
- Pangram识别AI内容的成本仅为每样本$0.0228
- OriginalityAI成本的一半($0.045)
- GPTZero费用的三分之一($0.068)
"策略上限"功能允许机构设置最大可接受错误率(如0.5%),Pangram是唯一能在这种限制下保持高准确性的系统。
关键要点:
- Pangram在所有测试的文本类型和长度中均表现出卓越准确性
- 开源检测器相比商业解决方案表现不佳
- 检测效果因来源AI模型而异
- 成本分析显示Pangram以每准确检测$0.0228提供最佳价值
- 研究人员建议随着AI生成工具的演进定期进行"压力测试"



