OpenAI Evals 现已支持原生音频输入与评估
OpenAI Evals 通过原生支持强化音频模型测试
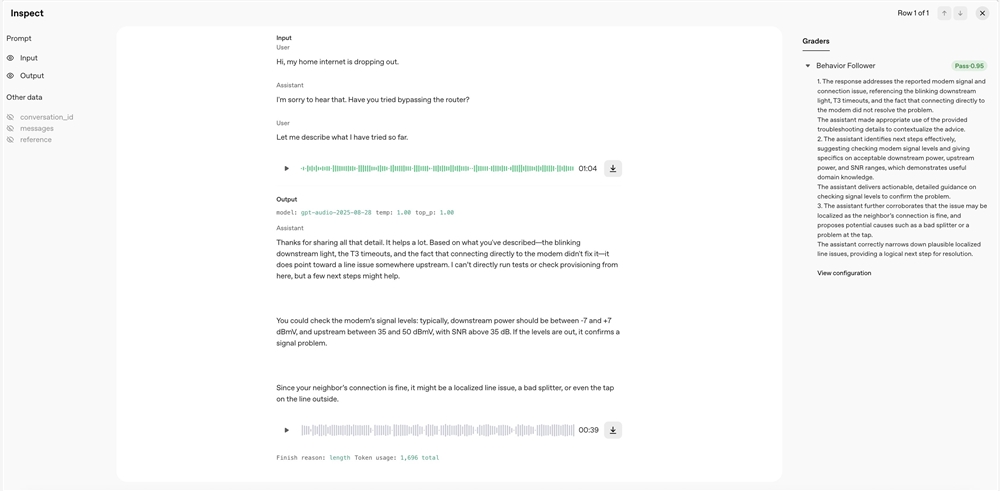
OpenAI 对其 Evals 工具进行了重大更新,新增 原生音频输入与评估功能。这一进步允许开发者直接上传音频文件来测试语音识别和生成模型,绕过了繁琐的转录过程。
为开发者简化工作流程
此前,评估音频模型需要将语音转换为文本——这一耗时步骤可能引入误差。借助新功能,开发者现在可以 直接上传音频文件 至平台,实现无缝的性能评估。该集成降低了数据处理复杂度并提高了结果可靠性。
跨行业的广泛应用
此次升级特别适用于:
- 智能语音助手:简化响应准确性的测试流程。
- 语音识别系统:更精确的性能评估。
- 音频内容生成:增强合成语音的质量控制。
开发者现在可以更快迭代,确保其产品在竞争激烈的市场中符合高质量标准。
开始使用音频 Evals
关于实施指南,OpenAI 建议参考其官方 Cookbook指南,其中提供了逐步说明和实用示例。
关键要点:
- 原生音频支持消除了转录瓶颈。
- 直接上传提高了 评估准确性 和速度。
- 该功能有益于 语音助手、语音转文本系统 和 生成式音频工具。