NVIDIA Canary-Qwen-2.5B创下语音识别新标杆
NVIDIA以Canary-Qwen-2.5B突破语音识别壁垒
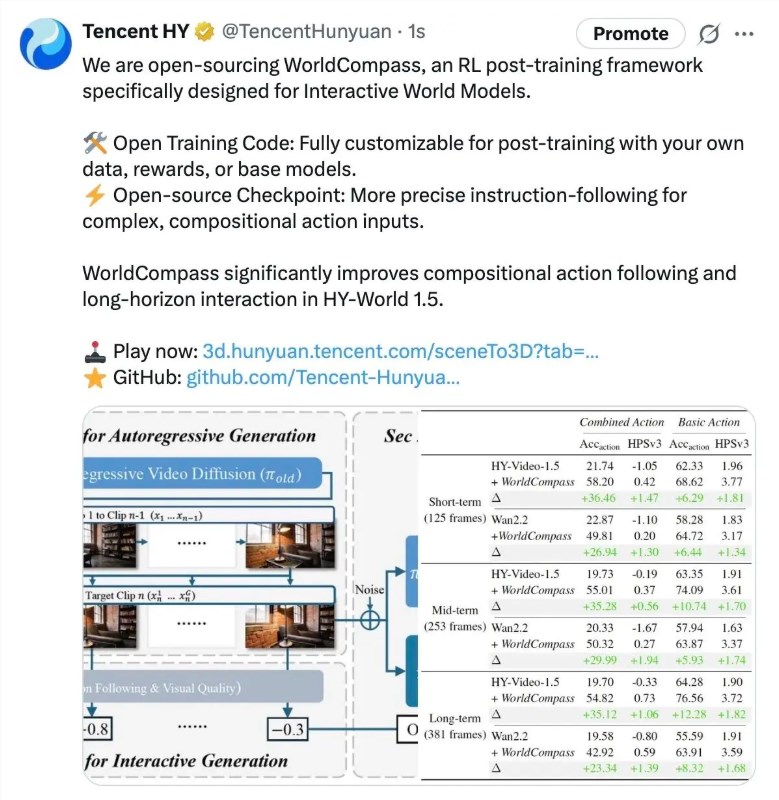
NVIDIA发布了Canary-Qwen-2.5B——一款融合自动语音识别(ASR)与大语言模型(LLM)能力的革命性混合模型,实现了行业领先的5.63%词错率(WER)。这一突破性表现目前高居Hugging Face OpenASR排行榜首位。
面向下一代语音AI的统一架构
该模型通过将转录与语言理解整合至单一架构,代表了重大技术进步。与传统需要分步处理的ASR系统不同,Canary-Qwen-2.5B支持直接音频理解能力,可完成摘要生成和问答等任务而无需中间文本转换。
性能亮点
确立Canary-Qwen-2.5B市场领先地位的关键指标:
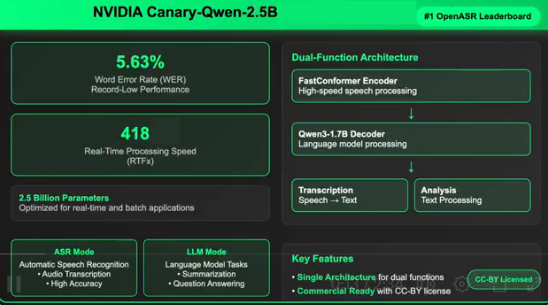
- 空前准确性:5.63% WER超越所有竞品
- 极速处理:RTFx达418(实时处理的418倍)
- 紧凑高效:仅25亿参数却实现卓越性能
- 全面训练:基于234,000小时多样化英语语音数据训练
混合设计创新
模型架构包含两个专业组件:
- FastConformer编码器:专为高精度、低延迟转录优化
- Qwen3-1.7B LLM解码器:通过适配器接收音频令牌的未修改预训练语言模型
模块化设计允许企业独立部署任一组件,同时保持语音与文本输入的多模态灵活性。
释放商业应用潜力
采用CC-BY许可发布的模型消除了企业应用壁垒,适用于:
- 专业转录服务
- 实时会议智能系统
- 合规文档处理(法律/医疗领域)
- 语音控制AI助手 集成LLM显著提升了标点符号、大小写及领域术语处理的上下文准确性。
跨平台硬件支持
解决方案针对NVIDIA全系GPU优化:
- 数据中心:A100/H100系列
- 工作站:RTX PRO6000
- 消费级:GeForce RTX 5090 这种可扩展性同时支持云端与边缘部署场景。
开放创新理念
通过开源模型架构与训练方法,NVIDIA鼓励开发领域专用变体社区。该方案开创了以LLM为核心的ASR新模式——语言模型成为语音转文本流程的核心部分而非后处理附加组件。
此次发布标志着向多模态全面理解的代理模型转型——使Canary-Qwen-2.5B成为下一代语音应用的基础设施。
核心要点:
— 创纪录5.63%词错率 — 音频处理速度达实时418倍 — ASR与LLM统一架构 — 采用商业友好的CC-BY许可 — 支持全系列NVIDIA硬件平台