东北大学翻译模型突破全球语言壁垒
东北大学在多语言AI翻译领域取得突破性进展
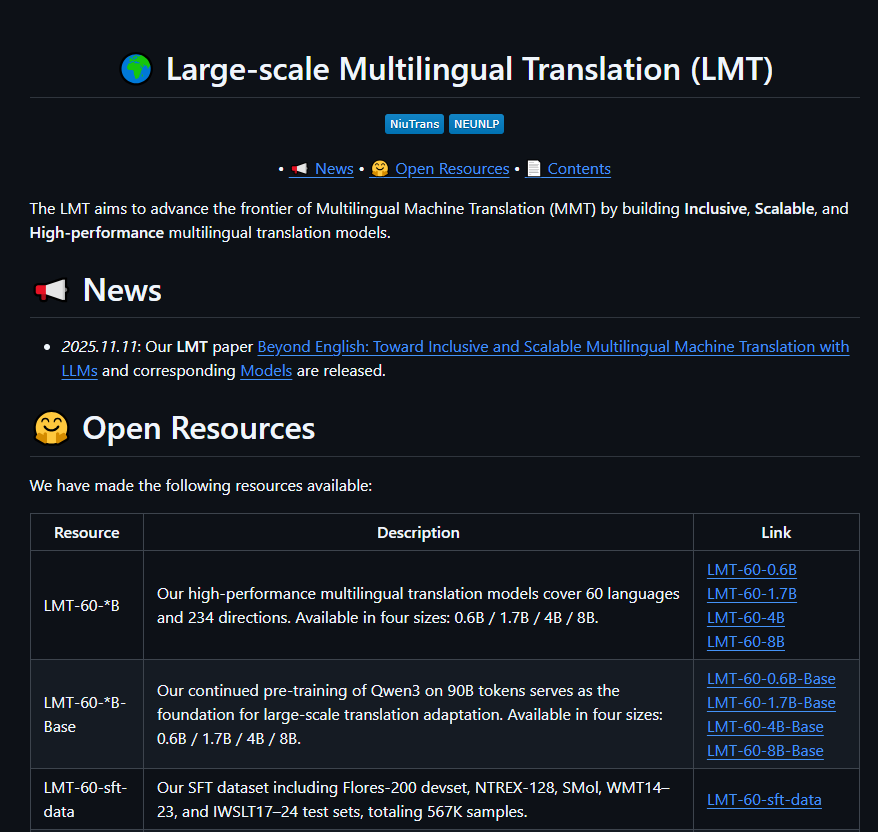
得益于东北大学的最新突破,世界的距离正被进一步缩短。其NiuTrans.LMT翻译模型现已连接60种语言,覆盖234个翻译方向——这一成果正在挑战传统翻译模式。
重构翻译架构
大多数翻译模型都通过英语中转,导致研究者所称的"语义坑洞"——多重转译中细微含义的流失。NiuTrans.LMT采用中英双中心设计开辟新路径:实现中文与其他58种语言、英文与其他59种语言的直接互译。
"想象用阿姆哈拉语解释一首藏文诗",首席研究员李伟博士表示,"过去需要藏→英→阿姆哈拉语的转译链,每步都有信息损耗。现在可以直接转换"。
让边缘化语言步入数字时代
研究团队将语言分为三个层级:
- 13种高资源语言(法语、阿拉伯语等):达到人类水平流畅度
- 18种中等资源语言(印地语、芬兰语):保持技术准确性
- 29种低资源语言(藏语、斯瓦希里语):从"不可译"迈向实用化
实现这一突破的创新训练方法包括:
- 持续预训练:平衡学习900亿多语言token
- 监督微调:使用覆盖117个方向的优质平行文本精调
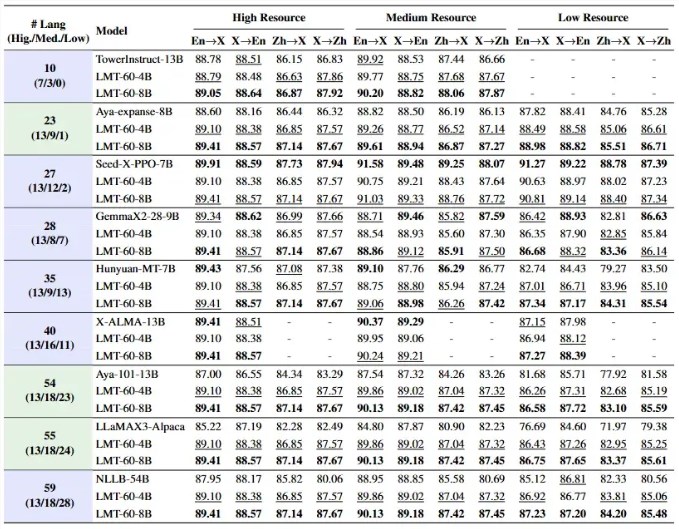
成果?在FLORES-200基准测试中位列开源模型榜首。
按需定制的可扩展方案
团队推出四个版本满足不同需求:
| 版本 | 适用场景 |
|---|
所有版本均在GitHub和Hugging Face免费提供。
超越技术——搭建文化之桥
这不仅关乎算法与代码。当埃塞俄比亚农民能阅读准确翻译的藏族诗歌,或北欧学者能原汁原味研读斯瓦希里谚语时,我们正在以数字形式保存文化遗产。
该项目体现了东北大学对"技术民主化"的承诺——李博士强调要让先进AI走出技术中心,服务全球需求。
核心亮点:
- 支持中文/英文分别与58/59种语言的直接互译
- 特别关注藏语、阿姆哈拉语等既往服务不足的语言
- 提供四种开源可扩展版本
- FLORES-200基准测试优于竞品
- 推动全球语言平等取得重大进展




