NeurIPS会议因虚假引用丑闻陷入信任危机
NeurIPS会议因虚假引用面临信誉危机
在这起震动人工智能研究界的丑闻中, prestigious NeurIPS会议卷入大规模引用造假事件。AI检测公司GPTZero发现51篇录用论文中共存在至少100个伪造参考文献——包括虚构作者和虚假出版信息。

'氛围引用'现象
研究人员将这种不良趋势称为"氛围引用"——作者添加看似合理但完全虚构的参考文献。部分论文列出"John Doe"等不存在作者,另一些则引用明显伪造的arXiv标识符(如arXiv:2305.XXXX)。这些幽灵引用尽管存在明显漏洞,却逃过了同行评审。
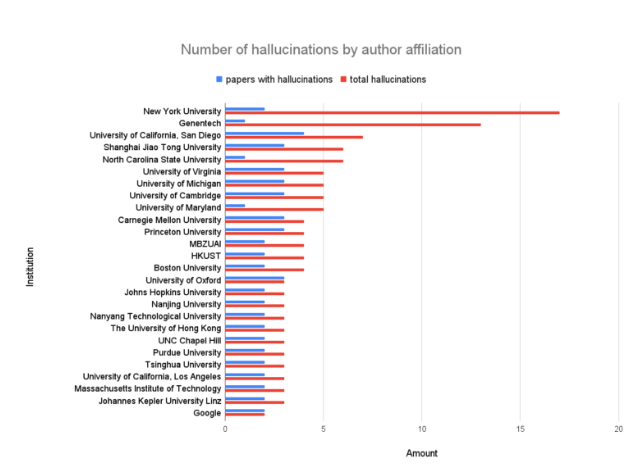
问题主要集中在纽约大学等顶尖机构和谷歌等科技巨头的投稿中。"尤其令人担忧的是这些本应达到最高标准的论文出现了问题,"一位熟悉调查的消息人士表示。
压力下的系统
该丑闻揭示了学术出版体系更深层的裂痕。NeurIPS投稿量从2020年的9,467篇飙升至今年的21,575篇——惊人的220%增长。这种稿件海啸迫使组织方招募大量缺乏经验的审稿人应对。
据报道部分审稿人走捷径使用AI工具而非仔细阅读投稿。"当被要求数周内评审数十篇复杂论文时,走捷径的诱惑难以抗拒,"一位匿名审稿人解释称。
后果与改革
NeurIPS已宣布将伪造引用作为拒稿或撤稿依据。但在以引用为学术货币的领域,信任损害可能更难修复。
该事件引发关于如何在AI研究指数级扩张下保持质量控制的难题。随着预印本服务器和会议被投稿淹没,传统同行评审体系显得日益吃紧。
关键点:
- NeurIPS51篇论文包含100+虚假引用
- 造假内容包括虚构作者和无效出版ID
- 自2020年以来投稿量翻倍增长,使审稿人不堪重负
- 会议组织方现视虚假引用为拒稿依据
- 丑闻凸显AI研究出版领域的成长阵痛
