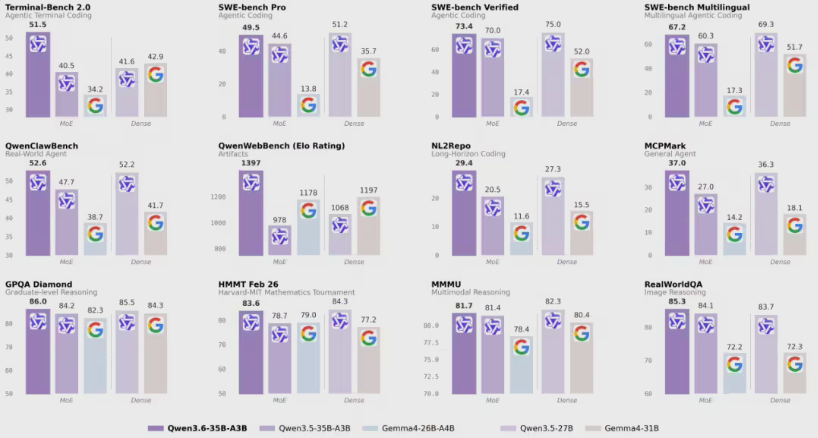
Moonshot AI与清华大学开创提升AI模型性能的新方法
Moonshot AI与清华大学破解AI处理加速密码
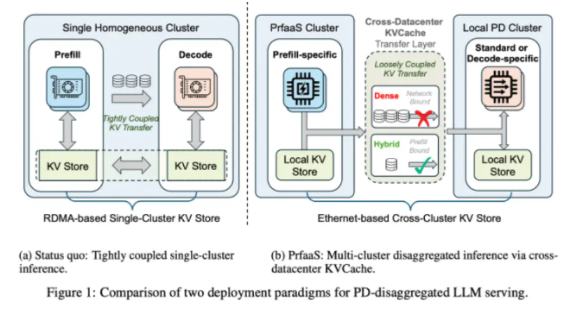
在人工智能领域的一次重大飞跃中,Moonshot AI与清华大学合作开发了一种全新方法,显著改进了大语言模型的运行方式。他们的预填充即服务(PrfaaS)架构有望解决AI部署中最顽固的难题之一——计算资源的低效使用。
长期拖慢AI速度的瓶颈
想象一家繁忙的餐厅,同一位厨师必须同时准备食材和烹饪菜肴。这基本上就是当前AI系统的运作方式,同时处理两项根本不同的任务:
- 预填充阶段:系统处理输入并准备其"记忆"(KVCache)的计算密集型工作
- 解码阶段:逐字生成回复的创造性过程
问题在于?这些阶段对硬件需求完全不同,却通常被塞进同一台服务器。就像试图背着负重跑马拉松——虽然可能,但远非最优解。
精准解决方案:拆分工作负载
研究团队的突破来自一个简单而激进的想法:如果我们在不同地点执行这些任务会怎样?PrfaaS就像一个精心编排的接力赛:
- 高性能计算集群处理密集的预填充工作
- 准备好的数据通过标准以太网安全传输
- 本地服务器随后专注于生成响应
"这种分离让每个组件都能专业化,"一位研究人员解释道,"就像装配线上有专门的工作站,而不是让一个工人包办所有事情。"
该系统采用智能调度技术,实时适应流量模式,即使在高峰使用期间也能防止瓶颈。早期测试显示在长文本内容生成方面效果尤为显著——这正是传统系统常常力不从心的领域。
实际影响:更快响应,更大容量
数据说明一切:
- 系统吞吐量提升54%
- 用户获得明显更快的首次响应
- 资源效率大幅提高
或许最重要的是,这种方法能更好地利用现有基础设施。数据中心现在可以在地理上分散工作负载,同时保持无缝性能——随着AI应用呈指数级增长,这是一个关键优势。
Moonshot AI与清华大学的合作不仅仅是一项技术成就。它为我们如何构建未来的分布式AI网络提供了蓝图,可能彻底改变从客服聊天机器人到科学研究工具等一切领域。
关键要点:
- PrfaaS将计算密集型和内存密集型的AI任务分配到不同服务器
- 使用标准以太网实现位置间高效数据传输
- 在降低延迟的同时提供54%更好的吞吐量
- 可能实现更可持续的AI基础设施扩展
- 为分布式计算网络开辟新可能性