微软开源VibeVoice TTS模型,具备突破性功能
微软发布具备行业领先能力的开源VibeVoice TTS模型
微软通过开源其VibeVoice文本转语音(TTS)模型,在人工智能领域掀起波澜。2025年8月26日发布的这一公告,引入了突破性的功能,推动了语音合成技术的边界。
前所未有的语音时长
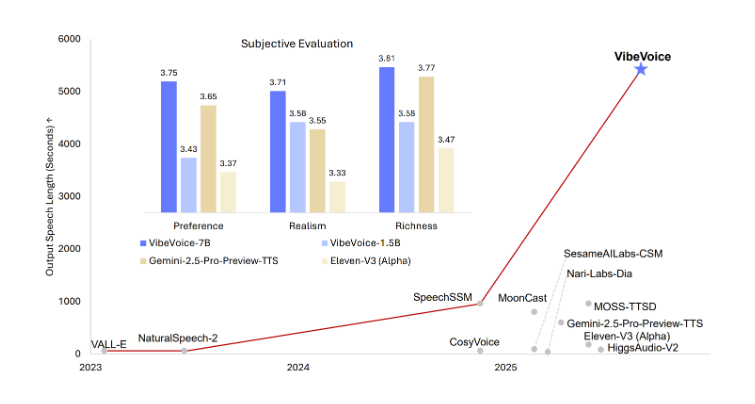
最显著的进步是VibeVoice能够生成长达90分钟的连续语音而不会出现质量下降。这一能力解决了现有TTS系统的一个关键限制,即通常在较长音频片段中难以保持一致性。延长的时长使该模型特别适用于:
- 有声书制作
- 教育内容创作
- 播客生成
- 长篇叙述项目
多说话人对话创新
VibeVoice通过支持多达四个不同声音的自然对话,为对话AI设立了新标准。这代表了从传统TTS系统(通常仅支持一到两个说话人)的重大飞跃。该模型在以下方面表现出色:
- 在不同说话人之间保持一致的音色特征
- 管理对话中的自然轮换
- 在长时间交流中保持情感语调
这项技术在虚拟会议模拟、互动叙事和多角色音频制作等应用中显示出特别的潜力。
卓越的中文语言表现
该模型在普通话中表现出色,具有精确的声调再现和自然的韵律。微软对中文语言支持的关注既反映了声调语言的技术挑战,也体现了中国市场在AI应用中的日益重要性。
主要优势包括:
- 复杂字符的准确发音
- 自然的节奏和语调模式
- 对正确词重音的上下文理解
- 方言感知的合成能力
增强的音频制作功能
VibeVoice集成了专业级的音频制作能力,包括:
- 背景音乐集成以创造沉浸式听觉体验
- 语音和音乐轨道之间的动态音量调整
- 不同音频元素之间的无缝过渡 这些功能使内容创作者无需额外的编辑软件即可制作出精美的音频输出。
开源可访问性
该模型在GitHub和Hugging Face(https://huggingface.co/microsoft/VibeVoice-1.5B)上的发布体现了微软对普及先进AI技术的承诺。开源方法提供了:
- 免费获取最先进的TTS技术的机会
- 社区驱动改进的机会
- 降低全球开发者的入门门槛
- 针对特定用例的定制潜力
此次发布响应了行业对更易获取和适应性更强的语音合成解决方案日益增长的需求。
## 关键点:
- 90分钟连续语音生成能力打破了之前的时长限制
- 四人对话支持实现了复杂的对话场景
- 卓越的中文语言表现满足了对本地化解决方案的日益增长的需求
- 专业音频功能包括背景音乐集成
- 开源可用性鼓励广泛采用和创新