微软开源Phi-4,超越GPT-4o和Llama-3.1
微软推出了Phi-4,一个小巧而强大的语言模型,只有140亿参数,现在可以在Hugging Face平台上使用。尽管体积紧凑,Phi-4在性能上表现出色,超越了包括OpenAI的GPT-4o和Qwen2.5及Llama-3.1等多个知名模型。
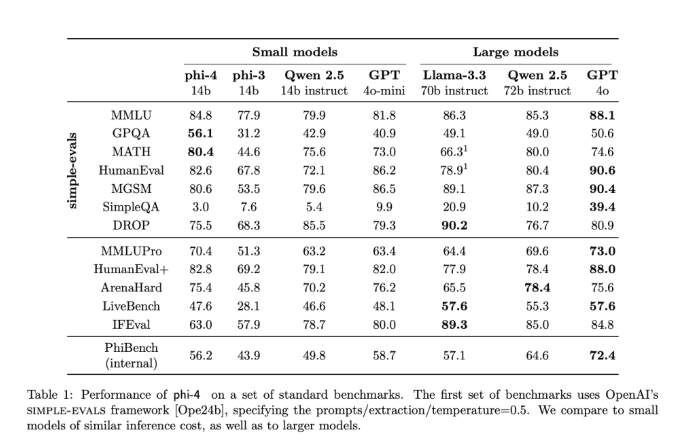
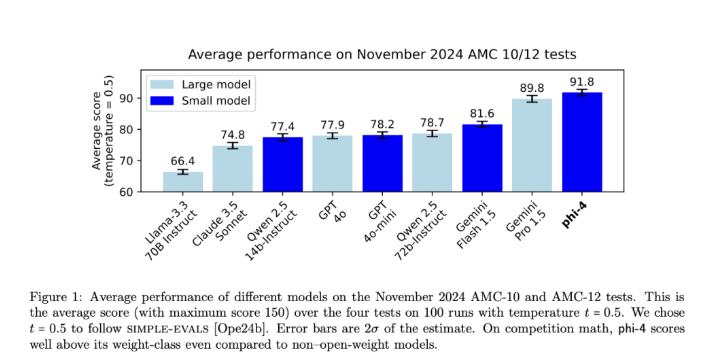
在严格的测试中,Phi-4在美国数学竞赛(AMC)等挑战中表现优异,得分91.8,超越了Gemini Pro1.5和Claude3.5Sonnet等竞争对手。该模型在MMLU测试中的表现也非常强劲,取得了84.8的优异分数,展示了其先进的推理和数学问题解决能力。
Phi-4通过使用合成数据生成技术(包括多智能体提示、指令反转和自我纠正方法)来实现差异化。这些创新提高了其推理能力,使Phi-4能够轻松处理复杂任务。与许多主要依赖自然数据的模型不同,Phi-4生成高质量的合成数据以优化其性能。
该模型基于仅解码器的Transformer架构,支持最长16k的上下文长度,能够高效处理大量输入数据。在预训练期间,Phi-4接触了大约1万亿个标记,这些标记结合了合成数据和经过精心挑选的自然数据,确保在MMLU和HumanEval等基准测试中表现出色。
Phi-4的优势不仅在于其体积和性能。它被设计为高效,兼容消费级硬件。它在STEM相关任务中的推理能力,尤其是在数学和科学方面,表现得特别令人印象深刻,超越了更小和更大的模型。此外,Phi-4可使用多种合成数据集进行微调,以满足特定领域的需求。
Phi-4背后的技术创新包括先进的数据生成技术,如多智能体提示和自我纠正,这些技术提高了其推理和问题解决能力。此外,该模型还利用后训练方法,如拒绝采样和直接偏好优化(DPO),优化其决策能力和在复杂推理任务中的表现。关键标记搜索(PTS)的引入帮助Phi-4识别关键的决策点,从而提高其准确性和推理能力。
Phi-4的开源发布标志着人工智能发展的重要一步。该模型可以在Hugging Face上下载,获得MIT许可证,允许商业使用。这一开放政策引起了AI社区的广泛关注,开发者和爱好者对Phi-4的性能和潜力给予了高度评价。Hugging Face的官方社交媒体账户甚至将其称为“有史以来最好的14B模型”。
模型链接:https://huggingface.co/microsoft/phi-4
关键点
- 微软的Phi-4模型仅有140亿参数,在性能测试中超越了GPT-4o和Llama-3.1等主要模型。
- Phi-4在数学和推理方面表现优异,在AMC和MMLU等测试中得分很高。
- 该模型是开源的,并获得商业使用许可,吸引了开发者和AI爱好者。