Meta新AI工具透视聊天机器人思维,修复推理缺陷
Meta突破:透视AI推理过程
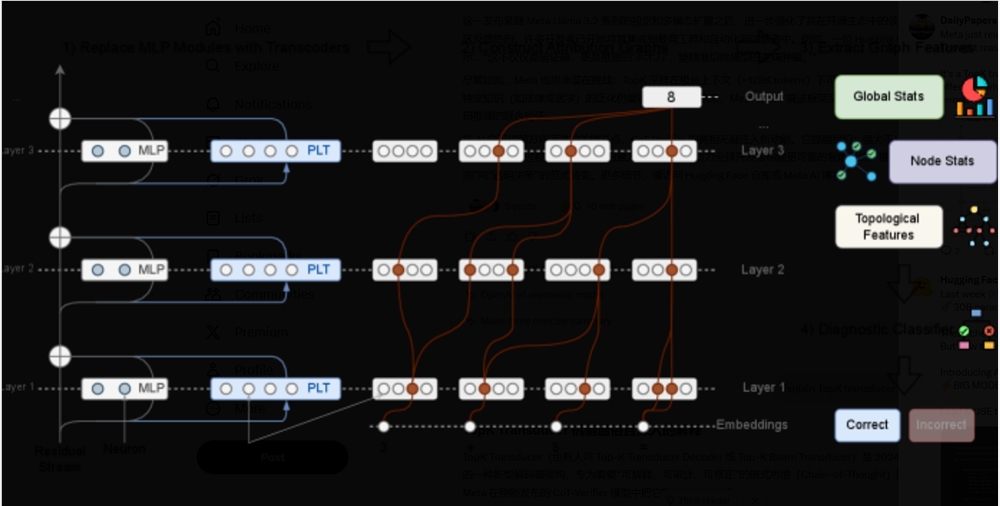
在AI透明度领域取得重大进展之际,Meta研究团队开发了一款堪称聊天机器人推理"X光机"的工具。他们最新发布的CoT-Verifier基于Llama3.18B Instruct架构构建,为开发者提供了前所未有的视角来观察大型语言模型的思考方式——更重要的是能发现逻辑断裂点。
现有方法的不足
迄今为止,检查AI推理通常意味着:
- 查看最终输出(黑盒)
- 或分析激活信号(灰盒)
"这就像仅通过听发动机声音来诊断汽车故障",首席研究员Mark Chen解释道,"你可能听出有问题,但无法确定是哪个活塞失火。"
Meta团队发现正确与错误的推理步骤在他们所称的归因图中留下了截然不同的"指纹"——本质上是模型内部处理信息的路径图。正确推理形成清晰高效的图案,而错误则产生混乱的迂回路径。
工作原理:突破背后的科学
该系统通过训练分类器识别这些结构模式来工作:
- 模式识别:该工具识别错误推理路径的特征标记
- 错误预测:在错误影响输出前进行标记
- 针对性修正:开发者随后可调整特定组件
早期测试显示该工具在需要多步逻辑的复杂任务中表现尤为突出,而传统方法往往会遗漏后续阶段积累的细微错误。
对AI发展的意义
这项技术的意义远超简单的错误检测:
- 新训练方法:模型可能从自身推理错误中学习
- 领域特定改进:数学任务与语言任务会呈现不同的错误模式
- 更智能AI的基础:理解失败模式有助于构建更健壮的系统
团队强调这不仅关乎修复当下的聊天机器人。"我们正在奠定基础",Chen表示,"未来能够解释自身思考过程的系统可能彻底改变从医疗诊断到法律分析的各个领域。"
CoT-Verifier现已在Hugging Face平台发布,Meta将持续完善其功能。
关键要点:
- 白盒可视化:首个展示LLM内部精确推理过程的工具
- 结构分析:识别正确/错误逻辑路径间的独特模式
- 超越检测:支持对缺陷推理组件的针对性修正
- 开放获取:现已登陆Hugging Face平台