Meta开源DINOv3:AI视觉领域的颠覆性突破
Meta开源DINOv3:自监督AI视觉的重大飞跃
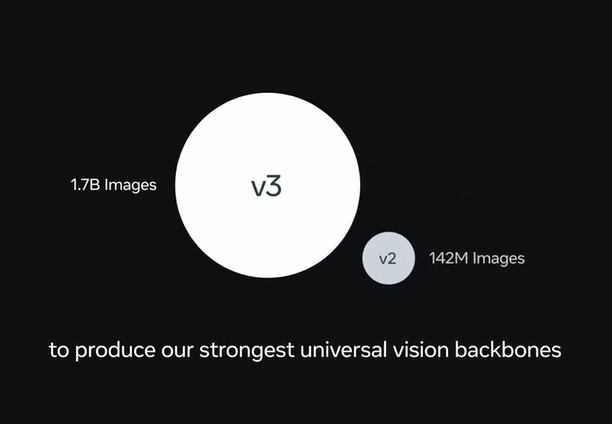
Meta AI正式开源了其新一代通用图像识别模型DINOv3,标志着计算机视觉技术的重大里程碑。与传统依赖人工标注数据的模型不同,DINOv3采用自监督学习从未标注图像中自主提取特征,既降低了数据准备成本,又扩展了应用范围。
自监督学习:范式转变
DINOv3的核心创新在于无需人工标注的训练能力。传统模型需要大量标注数据,而DINOv3通过直接从原始图像学习,达到了与SigLIP2、Perception Encoder等领先模型相当或更优的性能。这一突破在数据稀缺或标注成本过高的场景中尤为重要。

高分辨率特征提取
DINOv3擅长捕捉图像的全局和局部细节,可生成高质量的密集特征表示。这一能力支持广泛的视觉任务,包括:
- 图像分类
- 目标检测
- 语义分割
- 图像检索
- 深度估计
该模型的通用性不仅限于标准照片,还可处理卫星影像和医学图像等复杂数据类型,成为跨领域应用的强大工具。
广泛的行业应用
DINOv3的适应性为各行业带来变革性用例:
- 环境监测:分析卫星图像获取森林覆盖率和土地利用变化数据
- 自动驾驶:增强目标检测和场景理解以提高导航安全性
- 医疗保健:辅助病变检测和器官分割以改善诊断效果
- 安防监控:实现高级行为分析和人员识别功能
开源发布使中小企业和研究机构能够以可承受的成本使用尖端AI技术。
开源生态系统集成
Meta采用商业友好许可协议开放DINOv3,提供:
- 完整训练代码和预训练模型(参数规模从2100万至70亿)
- 支持PyTorch Hub和Hugging Face Transformers平台
- 评估代码及示例Notebook便于快速上手 开发者称赞该模型在Hugging Face生态系统中出色的易用性和性能表现。
伦理考量
尽管DINOv3潜力巨大,但专家提醒需警惕隐私侵犯和算法偏见等风险。随着技术普及,解决这些伦理挑战将至关重要。
关键要点:
- 无需人工标注:通过自监督学习训练,减少对标注数据的依赖
- 高分辨率特征:同时捕捉全局上下文与细粒度细节
- 跨领域通用性:适用于医学影像、自动驾驶等多种场景
- 开源访问:提供预训练模型和教程降低开发者门槛
- 伦理警惕性:需谨慎部署以规避隐私和偏见问题