美团LongCat发布UNO-Bench:多模态AI评估新基准
美团LongCat团队推出突破性AI评估工具
2025年11月6日,北京 - 美团LongCat研究团队发布了UNO-Bench,这是一个革命性的基准测试工具,旨在系统评估多模态大语言模型(MLLMs)。这一新工具代表了在评估AI系统跨模态理解和处理信息能力方面的重大进展。
全面评估框架
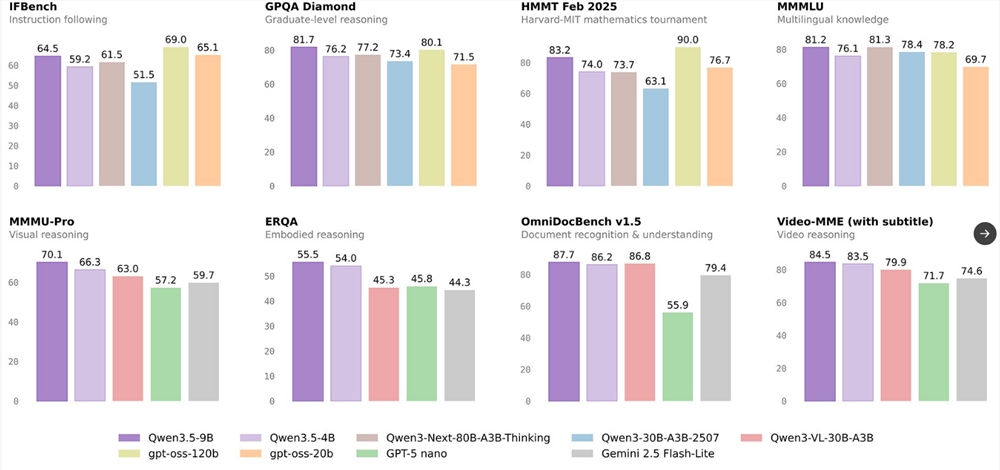
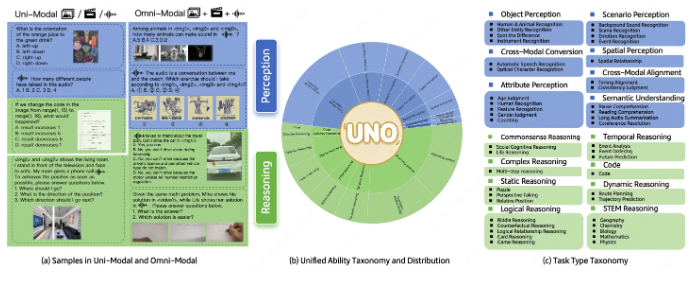
该基准涵盖44种不同任务类型和五种模态组合,为研究人员提供了前所未有的工具来测量模型在单模态和全模态场景下的表现。开发团队表示,UNO-Bench的创建是为了满足随着多模态AI系统日益复杂化而对标准化评估指标日益增长的需求。
强大的数据集设计
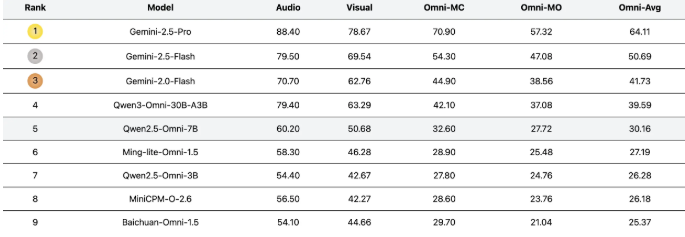
UNO-Bench的核心是其精心策划的数据集:
- 1250个全模态样本,具有98%的跨模态可解性
- 2480个增强的单模态样本,针对实际应用进行了优化
- 特别强调中文语境下的表现
- 自动压缩处理使得运行速度提升90%
该数据集在针对18个公共基准测试时保持了令人印象深刻的98%一致性率,证明了其在研究用途上的可靠性。
创新评估方法
UNO-Bench引入了多项突破性功能:
- 多步开放式问题格式用于评估复杂推理能力
- 通用评分模型能够自动评估六种不同问题类型
- 在自动评估中达到95%准确率
未来发展计划
虽然目前主要关注中文应用场景,但LongCat团队正在积极寻求国际合作伙伴以开发:
- 英文版本
- 多语言适配版本
完整的UNO-Bench数据集现已可通过Hugging Face平台下载,相关代码和文档可在GitHub上获取。
关键点:
- UNO-Bench通过44种任务和5种模态组合评估多模态AI
- 包含具有98%跨模态可解性的精选数据集
- 引入创新的多步问题格式
- 目前专注于中文版本,计划开发英文/多语言版本
- 现已在Hugging Face和GitHub上提供