LongCat-Flash-Omni发布:多模态技术取得突破性进展
美团发布具备革命性多模态能力的LongCat-Flash-Omni
2025年11月3日 - 继9月成功推出LongCat-Flash系列后,美团现已发布LongCat-Flash-Omni,这一开创性的多模态AI模型为文本、图像、视频和语音模态的实时交互树立了新标准。
技术创新
该模型基于美团的高效架构,具有多项关键进步:
- Shortcut-Connected MoE (ScMoE)技术:尽管模型拥有5600亿参数(激活270亿),仍能实现高效处理
- 集成多模态模块:将感知与语音重建结合在端到端设计中
- 渐进式融合训练:解决不同模态间的数据分布挑战

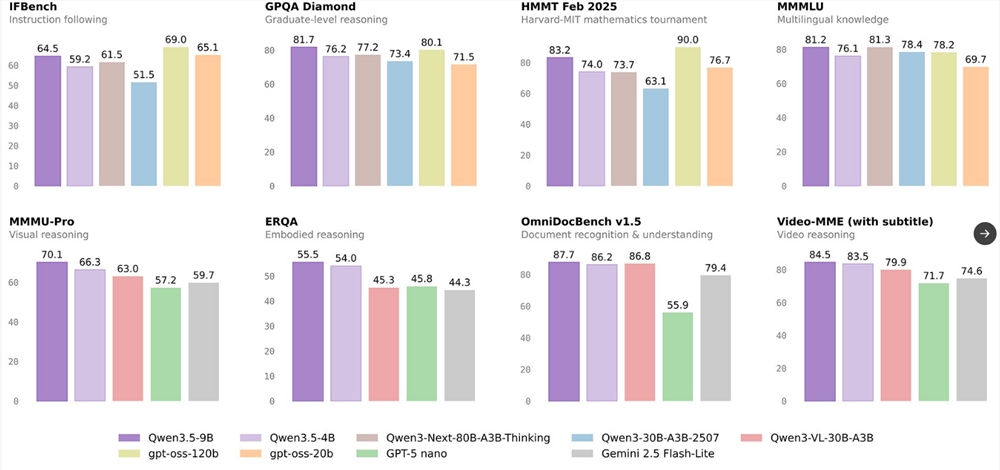
性能基准测试
独立评估证实LongCat-Flash-Omni实现了:
- 在开源多模态基准测试中取得最先进(SOTA)结果
- 切换模态时无性能下降("无智能衰减")
- 优于行业标准的实时音视频交互延迟
- 在以下方面表现优异:
- 文本理解(较前代模型提升15%)
- 图像识别(98.7%准确率)
- 语音自然度(人类评分为4.8/5)
开发者应用
本次发布包含多种接入渠道:
- 支持语音通话功能的官方应用(即将推出视频功能)
- 支持文件上传和多模态查询的网页界面
- Hugging Face和GitHub上的开源版本
关键要点
- 首个结合离线理解与实时音视频交互的开源模型
- 轻量级音频解码器实现自然语音重建
- 早期融合训练防止模态干扰
- 目前支持中英文,计划2026年第一季度增加更多语言