李沐团队发布Higgs Audio v2,革新语音合成技术
李沐团队发布Higgs Audio v2,革新语音合成技术
著名AI企业家李沐及其Boson.ai团队推出突破性开源文本转语音(TTS)模型Higgs Audio v2。该版本标志着语音合成技术的重大飞跃,提供多语言对话生成、自动节奏调节和声音克隆等创新功能。
多模态能力
Higgs Audio v2以其多模态功能脱颖而出。与传统TTS系统不同,它能在理解上下文的同时处理文本并生成语音。例如,它可以创作歌曲、用特定声线演唱,甚至添加背景音乐——这是TTS技术此前难以实现的壮举。

性能基准测试
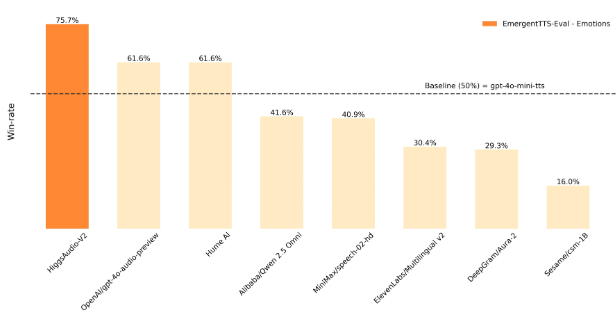
该模型基于1000万小时语音数据训练,在各基准测试中表现卓越。根据EmergentTTS-Eval测试结果,Higgs Audio v2在"情感"类别中超越GPT-4o-mini-tts达75.7%,在"问答"类别领先55.7%,为传统TTS测试树立了新的行业标准。
技术创新
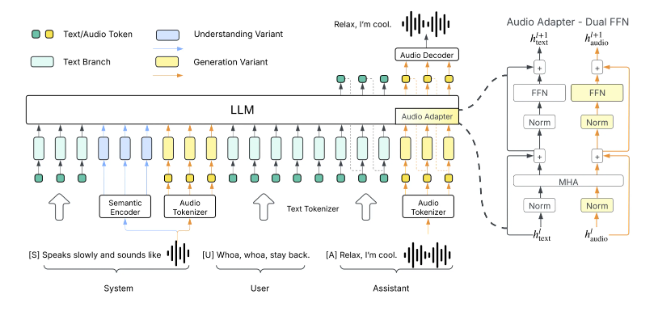
Higgs Audio v2采用先进数据处理技术:
- 通过离散音频标记器以每秒25帧的速度将音频信号转化为数字序列
- 精准捕捉语义与声学特征
- 依托预训练大语言模型增强语言理解与上下文把握能力
- 支持零样本声音克隆,仅需少量提示即可适应新任务
实际应用场景
该模型在现实场景中表现优异:
- 实时语音聊天: 凭借低延迟和高情感表现力,成为虚拟主播与语音助手的理想选择
- 音频内容创作: 为有声书、互动培训和动态叙事生成自然对话
- 声音克隆: 复制特定声线,为娱乐和创意产业开辟新可能
代码已在GitHub和Hugging Face**开源****支持通过GPU版PyTorch或Docker进行本地部署。
核心亮点:
- Higgs Audio v2开创具备声音克隆与节奏调节的多模态TTS系统
- 千万小时数据训练使其在关键基准测试中全面领先竞品
- 先进标记化技术与预训练模型确保高精度与强适应性
- 开源特性推动实时聊天与内容创作领域的创新