昆仑万维开源Skywork-Reward-V2奖励模型
昆仑万维开源Skywork-Reward-V2奖励模型
2025年7月4日,昆仑万维正式开源第二代奖励模型——Skywork-Reward-V2,标志着开源AI工具的重大进步。该系列包含8个参数规模从6亿到80亿不等的模型,在七大主流评估基准中均取得顶尖排名。
高质量数据集与训练流程
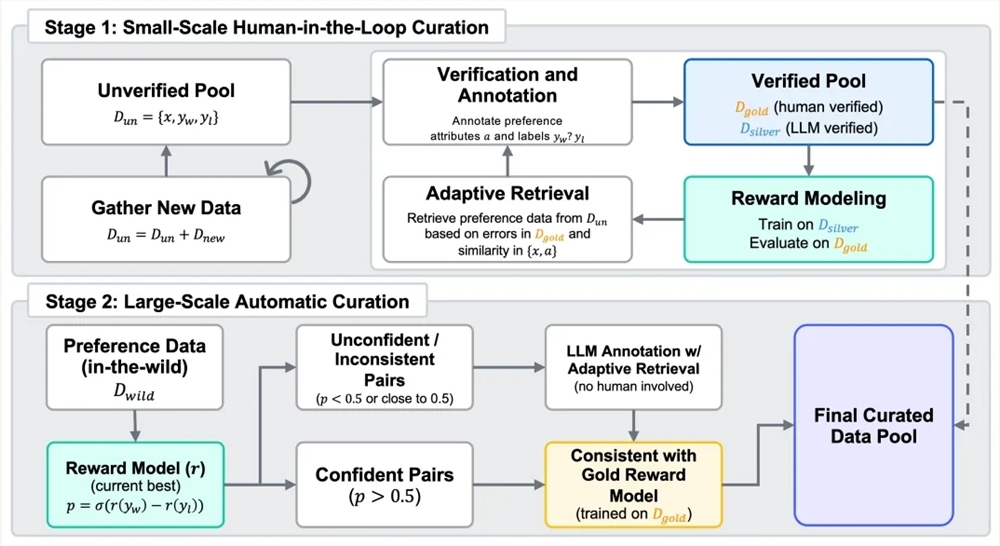
Skywork-Reward-V2的开发基于混合数据集Skywork-SynPref-40M,其中包含4000万对偏好对比数据。团队采用两阶段人机协作流程:
- 初始阶段:通过大语言模型(LLM)构建未验证偏好池辅助标注属性,再经人工严格审核形成高质量"黄金标准"数据集
- 扩展阶段:自动化生成大规模数据,利用训练好的奖励模型进行一致性过滤以平衡规模与质量
性能表现与核心能力
Skywork-Reward-V2系列在以下维度表现卓越:
- 与人类偏好的普适对齐性
- 客观正确性
- 安全性与抗偏见能力
- Best-of-N扩展性
最小模型(Skywork-Reward-V2-Qwen3-0.6B)即可达到上一代最强模型的平均水准,而最大模型(Skywork-Reward-V2-Llama-3.1-8B)则超越所有主流基准。
关键创新点
- 可扩展性:数据筛选流程提升模型表现,迭代训练显示显著改进效果
- 高效性:早期实验表明,仅用1.8%高质量数据训练的8B模型性能已超越700B参数的SOTA模型
- 多功能性:覆盖知识密集型任务和复杂指令理解等多重维度
获取方式
模型可通过以下平台获取:
核心亮点
- 顶尖性能:在七大基准测试中实现SOTA指标
- 混合数据集:融合人类专家知识与LLM的扩展能力
- 广泛适用性:涵盖安全性、抗偏见和正确性等多重领域