IBM与Hugging Face推出SmolDocling:文档转换领域的革命性突破
在计算机科学领域,将复杂文档转换为结构化数据一直是一个重大挑战。传统方法通常涉及繁琐的工作流程,或依赖于容易出错且计算成本高的大型多模态模型。然而,一种新的解决方案出现了:SmolDocling,这是由IBM和Hugging Face合作开发的项目,有望彻底改变这一领域。
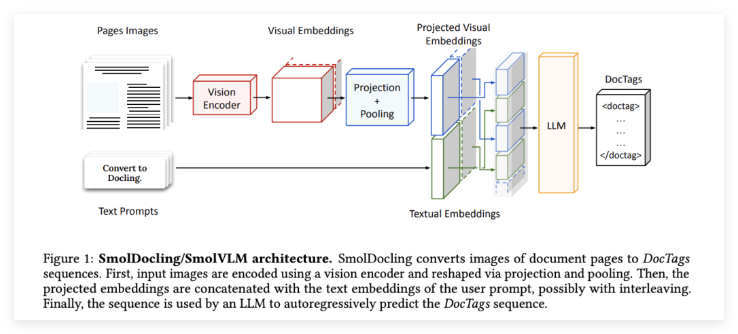
SmolDocling是一个256M参数的开源视觉语言模型(VLM),旨在为多模态文档转换提供端到端的解决方案。与拥有数十亿参数的更大模型不同,SmolDocling的紧凑尺寸使其成为一种轻量级但功能强大的工具,显著降低了计算复杂性和资源需求。
SmolDocling的独特方法
该模型的关键创新在于其DocTags格式,这是一种通用的标签系统,能够以清晰简洁的方式捕捉页面元素、其结构和空间上下文。这一特性使得机器能够精确理解文档布局、文本内容以及表格、公式、代码片段和图表等视觉元素。
基于Hugging Face的SmolVLM-256M,SmolDocling利用优化的分词和激进的视觉特征压缩来最小化计算需求。其训练过程采用课程学习——从冻结的视觉编码器开始,逐步使用更丰富的数据集进行微调,以增强视觉语义对齐。值得注意的是,SmolDocling在消费级GPU上平均每页处理时间为0.35秒,消耗不到500MB的显存。
轻量级冠军
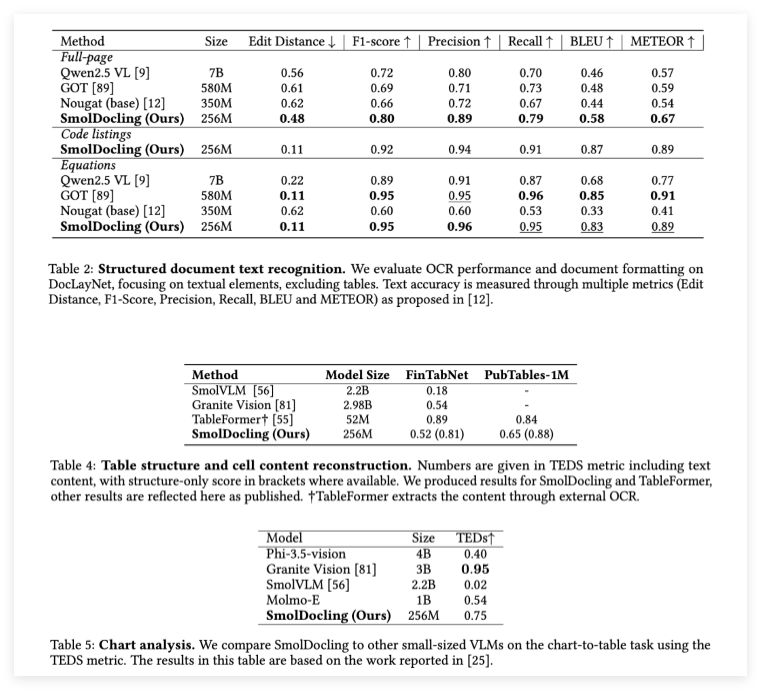
在基准测试中,SmolDocling表现出了卓越的性能。例如,在全页文档OCR中,它超越了Qwen2.5VL(70亿参数)和Nougat(3.5亿参数)等更大的模型,实现了更低的编辑距离(0.48)和更高的F1分数(0.80)。在公式转录中,它以F1分数为0.95的表现与最先进的模型持平。此外,它在代码片段识别方面设定了新标准,精确率和召回率分别达到0.94和0.91。
处理复杂文档的多功能性
SmolDocling的能力不仅限于科学论文,还包括专利、表格、商业文档等。它处理代码、图表和多样化布局等复杂元素的能力使其与传统OCR解决方案区别开来。通过提供全面的结构化元数据(通过DocTags),SmolDocling消除了HTML或Markdown等格式中固有的歧义性,增强了下游可用性。
该模型的紧凑尺寸还使其能够在资源需求最小的情况下进行大规模批量处理,为处理大量复杂文档的企业提供了经济高效的解决方案。
结论
SmolDocling代表了文档转换技术的一项重大突破。它表明紧凑模型不仅能够与大型基础模型竞争,还能在某些关键任务中超越它们。其开源性质为OCR技术的效率和多功能性设定了新标准,同时通过开放数据集和高效的模型架构为社区提供了宝贵的资源。
关键点
- SmolDocling是由IBM与Hugging Face开发的256M参数开源视觉语言模型。
- 它引入了DocTags格式以实现对文档元素的精确机器理解。
- 该模型在消费级GPU上每页处理时间为0.35秒且显存使用极少。
- 它在OCR、公式转录和代码识别任务中超越了更大的模型。
- SmolDocling的多功能性使其适用于处理专利、商业文档和科学论文等场景.