HydraDB 融资650万美元,以更智能的存储技术重塑AI记忆
AI记忆存储的全新方案
在人工智能基础设施的重大进展中,HydraDB宣布获得650万美元融资,旨在革新AI系统存储和检索信息的方式。这家初创企业的技术直指当前AI记忆解决方案普遍存在的致命缺陷。
现有系统的问题
当今的AI助手通常依赖将对话分解成片段并分别存储的向量数据库。这些系统擅长寻找相似内容,但在识别真正相关信息时往往表现糟糕。
想象一下:当你要求AI助手调取特定合同时,却收到一份格式完美但完全错误的他人文件。这就是基于相似性搜索的恼人现实——它们能识别匹配模式,却遗漏关键的上下文关系。
HydraDB受人类启发的解决方案
HydraDB团队从人类记忆的实际运作方式中汲取灵感,而非将人工构造强加于机器学习系统。他们的方法结合了三大关键创新:
关系映射优于片段存储 不同于将信息切割成孤立碎片,HydraDB在概念间建立智能连接。它能理解"就职于A公司"和"居住在纽约"描述的是同一个人,而非两个独立数据点。
Git式记忆版本控制 当信息变更时,HydraDB不会像传统数据库那样简单覆盖旧数据。如同代码的Git版本控制,它在添加新信息的同时保留历史上下文——既记录你的旧地址,也保存搬迁原因。
自动上下文标记 每条记忆都自带上下文理解能力。如果你说"我讨厌那个框架",系统会自动将其关联到你之前关于React.js的讨论,而无需明确澄清。
为何此刻至关重要
随着企业日益依赖需要精确长期记忆的AI助手和知识管理系统,这一技术的问世恰逢其时。早期测试表明,HydraDB可显著减少那些因表面相似性导致AI自信提供错误答案的尴尬时刻。
本轮投资将加速产品在三个关键领域的开发和部署:个人AI助手、企业知识库以及企业应用中使用的检索增强生成(RAG)系统。
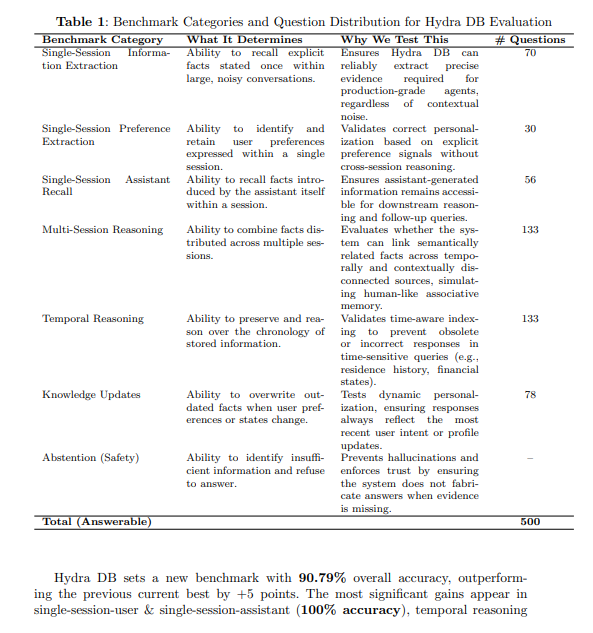
详细阐述HydraDB技术方案的论文可在此查阅。随着该公司从研究转向实施阶段,业内众多观察者将密切关注这一前景广阔的理论能否转化为实际改进。
核心要点:
- 650万美元融资验证市场对更优AI记忆方案的迫切需求
- 关系图谱取代碎片化存储方式
- Git式版本控制智能保留历史上下文
- 自动上下文标记减少对话误解
- 应用潜力涵盖从个人助手到企业知识系统