Hugging Face发布SmolLM3:一款媲美大型模型的紧凑型AI模型
Hugging Face推出SmolLM3:高效AI新标杆
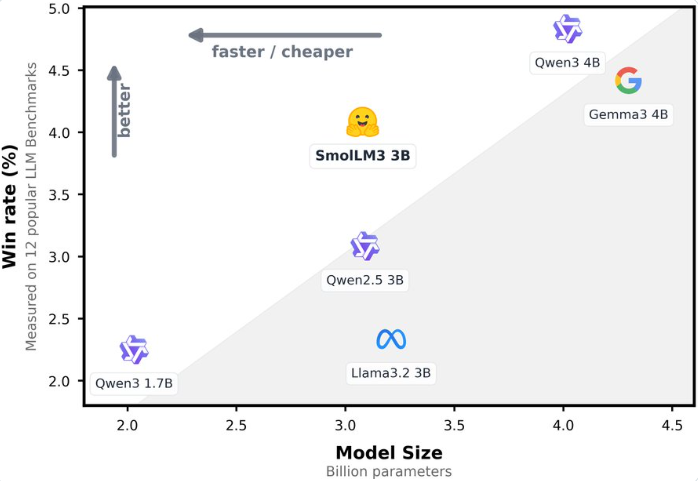
Hugging Face正式发布SmolLM3,这款突破性的开源语言模型挑战了关于模型规模与性能的传统认知。仅凭30亿参数,这款轻量级大语言模型(LLM)展现出与Gemma3等40亿参数大型模型相当的性能,同时提供更优的效率和灵活性。
超越体型的性能表现
SmolLM3代表了小模型技术的重大飞跃。作为仅解码器Transformer架构,它融合了分组查询注意力(GQA)和NoPE等先进技术来优化推理效率与长上下文处理。基于包含网页内容、代码、数学和推理数据在内的11.2万亿token训练数据集,SmolLM3在知识密集型任务中表现卓越。
基准测试显示惊人结果:在HellaSwag、ARC和BoolQ等知识与推理评估中,SmolLM3不仅超越Llama-3.2-3B和Qwen2.5-3B等同类模型,更达到或超过40亿参数大型模型的水平。
创新双模功能
SmolLM3最显著的特性是其双模推理系统,提供"思考"(think)与"非思考"(no-think)两种模式。这项创新允许模型根据任务复杂度动态调整策略:
- 在思考模式下,模型在挑战性基准测试中表现大幅提升:
- AIME2025: 36.7%准确率 vs 标准模式9.3%
- LiveCodeBench: 30.0% vs 15.2%
- GPQA Diamond: 41.7% vs 35.7%
这种灵活性可在不同应用场景中实现速度与分析深度的最优平衡。
扩展上下文与多语言能力
通过YaRN技术从原生64K训练容量扩展至128K token上下文窗口,该模型为小规模模型树立了新标准。这使得SmolLM3特别适合处理长文档或维持对话上下文。
多语言支持是另一大优势:除六种原生语言(英语、法语、西班牙语、德语、意大利语、葡萄牙语)外,还接受阿拉伯语、中文和俄语的专项训练。Global MMLU和Flores-200测试指标证实其处于同规模多语言模型的领先地位。
完全开源承诺
秉承Hugging Face理念,SmolLM3以完全透明的方式发布:
- 公开模型权重
- 开源11.2万亿token训练数据组合
- 完整披露训练配置与代码
公司提供这套全面的"训练蓝图"显著降低了学术研究与商业应用的准入门槛,同时促进开发者社区的创新活力。
为边缘计算优化设计
模型的效率设计特别适合资源受限环境:
- 通过分组查询注意力机制减少KV缓存占用
- WebGPU兼容性支持浏览器端部署
- 性能与计算成本的理想平衡为以下场景创造新可能:
- 教育应用
- 编程辅助工具
- 客户支持系统
- 边缘设备集成
本次发布实现了Hugging Face所说的"帕累托最优"——能力与资源需求的完美平衡点。
行业影响与未来潜力
SmolLM3的推出标志着AI领域的重大转变,证明经过优化的轻量模型同样能取得竞争力表现。其综合特性对以下群体极具吸引力:
- 需要透明模型的学术研究者
- 寻求成本效益解决方案的初创企业
- 实施本地化AI部署的大型机构
全开源模式可能推动行业透明度提升,并通过社区贡献加速创新发展。
核心亮点:
- 紧凑强者: SmolLM3仅30亿参数即通过先进优化技术达到或超越诸多40亿模型的性能表现。
- 灵活智能: 双模推理根据任务复杂度自适应——需要时快速响应,难题则深度分析。
- 扩展语境: 业内领先的128K token容量使小框架内实现复杂文档处理成为可能。
- 全球适用: 九种语言的强大支持为其国际部署奠定基础。
- 开发者友好: 包含权重、数据组合及训练细节的完整开源释放定制化创新潜力。