Grok4在推理能力上超越GPT-5,但成本更高
AI模型对决:最新基准测试中的性能与成本
来自ARC Prize的新测试数据为人工智能领域的发展提供了关键洞察,揭示了主流语言模型在性能和运营成本上的显著差异。这项全面评估将xAI的Grok4与OpenAI的GPT-5在多维度基准测试中进行了对比,测量了通用推理能力。
基准测试解析:被验证的推理能力
在评估复杂推理能力的严苛ARC-AGI-2测试中:
- Grok4(思考模式)以每任务2-4美元的成本取得16%准确率
- GPT-5(高级版)仅花费0.73美元每任务就获得9.9%准确率
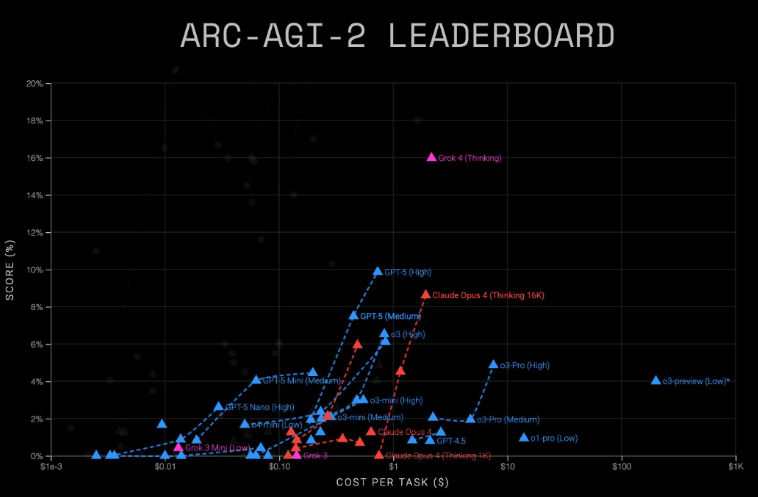 主流语言模型在ARC-AGI基准测试中的性能与成本对比 | 图片来源:ARC-AGI
主流语言模型在ARC-AGI基准测试中的性能与成本对比 | 图片来源:ARC-AGI
强度较低的ARC-AGI-1测试显示:
- Grok4达到68%准确率(每任务1美元)
- GPT-5取得65.7%准确率(每任务0.51美元)
"虽然Grok4展现出更优越的推理能力,但其成本结构使得GPT-5对多数应用更具经济可行性",ARC Prize发言人指出。
轻量级竞争者崭露头角
研究还评估了小型模型变体:
| 模型 | AGI-1得分 | AGI-1成本 | AGI-2得分 | AGI-2成本 |
|---|
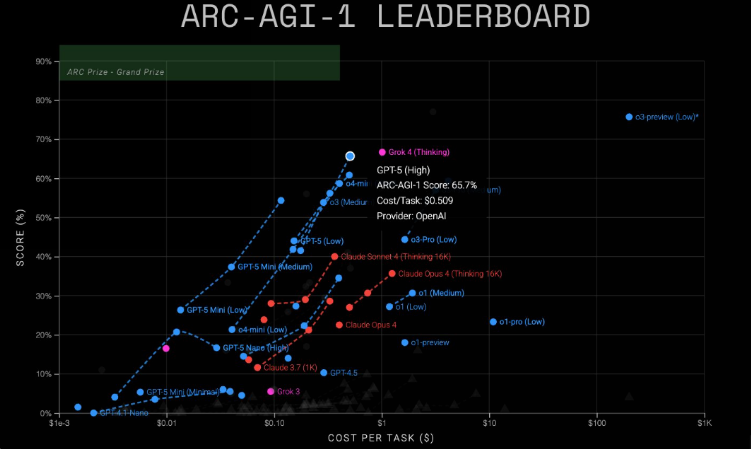 Grok4、GPT-5及小型变体模型在ARC-AGI-1上的测试结果 | 图片来源:ARC Prize
Grok4、GPT-5及小型变体模型在ARC-AGI-1上的测试结果 | 图片来源:ARC Prize
意外表现者与未来测试
已停产的2024年12月版o3-preview模型意外地在AGI-1上以近80%准确率超越所有现有模型,尽管定价较高。与此同时,ARC-AGI-3的开发仍在继续——该测试将在交互式游戏环境中评估AI代理的表现,这是目前多数模型相较人类仍显薄弱的领域。
关键要点:
- 性能领先:Grok4在推理任务中以显著优势超越GPT-5(AGI-2测试中16%对比9.9%)
- 成本效益:GPT-5在所有测试中保持更优性价比(AGI-1测试中$0.51对比$1)
- 轻量选择:小型GPT变体为成本敏感型应用带来希望
- 未来基准:新型交互式测试环境可能重塑性能排名