Grok4.20 Beta版以创纪录的低幻觉率首次亮相
xAI通过Grok4.20 Beta版发布提高标准
2026年3月12日,埃隆·马斯克的xAI发布了Grok4.20 Beta版,此举可能重塑人们对AI可靠性的期望。新模型拥有行业领先的事实准确性,同时保持极具竞争力的价格优势。
基准测试突破
最突出的特点是什么?78%的非幻觉率——意味着该模型捏造信息的频率远低于同类产品。Artificial Analysis的独立评估人员给Grok4.20的推理能力打了48分的智能指数,比前代产品提高了6分。
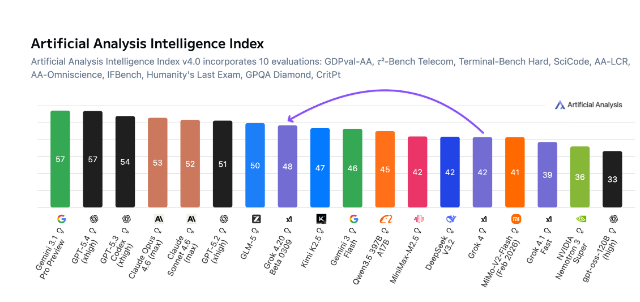
虽然在综合测试中仍落后于谷歌的Gemini3.1Pro Preview和OpenAI的GPT-5.4(两者均为57分),但Grok4.20在AA全能测试等专项评估中展现出特别的优势。
实际改进
xAI推出了三种API版本以满足不同需求:
- 标准推理能力模型
- 轻量级非推理选项
- 高级多代理配置
这些模型支持高达200万token的上下文窗口,价格从每百万token 2美元到6美元不等——比之前的版本实惠得多。

对于厌倦了AI过度自信的用户来说,最令人耳目一新的是Grok4.20在不确定时表现出异常的克制——说"我不知道"的频率是早期模型的五倍。
竞争格局的变化
此次发布凸显了AI军备竞赛如何从纯粹的参数数量转向平衡能力与可靠性。通过优先考虑准确性而非花哨的功能,xAI似乎在赌企业最看重的是可信的输出结果。
这种对事实完整性的强调可能对以下领域特别有价值:
- 需要精确数据的金融服务
- 错误会带来后果的医疗应用
- 法律和合规用例
该模型以诚实为中心的设计也为更可靠的多代理系统奠定了基础——随着AI协作变得越来越普遍,这一点至关重要。
关键点:
- 78%的非幻觉率树立了新的行业标准
- 48分的推理得分显示提高了6分
- 三种API版本满足不同需求和预算
- 竞争性定价起价为每百万token 2美元
- 更愿意承认不确定性标志着行为转变