谷歌Gemini 3 Deep Think智商碾压除七人外的全人类
谷歌新AI模型接近人类水平推理能力
随着谷歌公布其Gemini 3 Deep Think模型的重大升级,人工智能领域今日发生巨变。这个专注于跨领域复杂问题解决的系统展现出媲美——有时甚至超越——人类专家的能力。
令人瞩目的编程实力
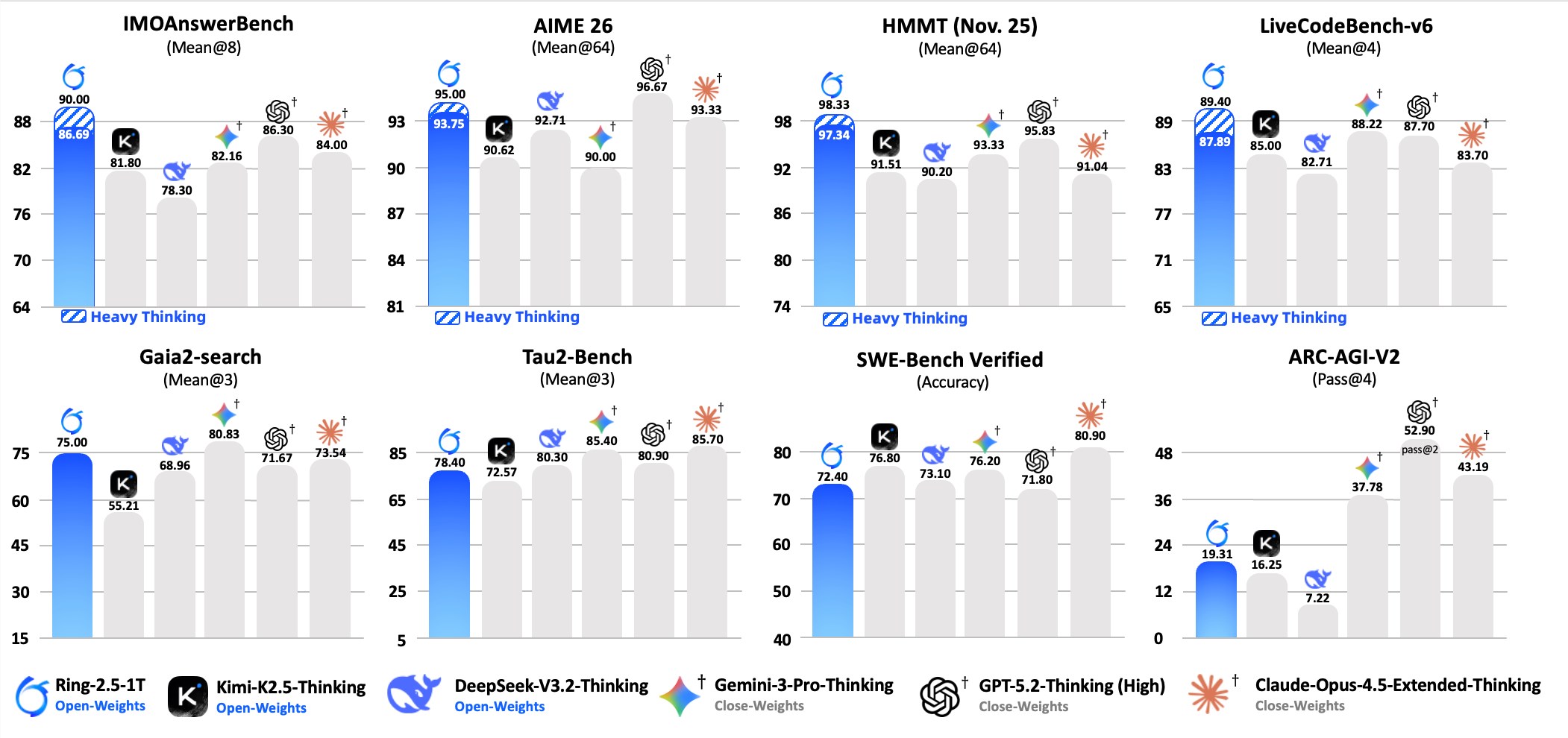
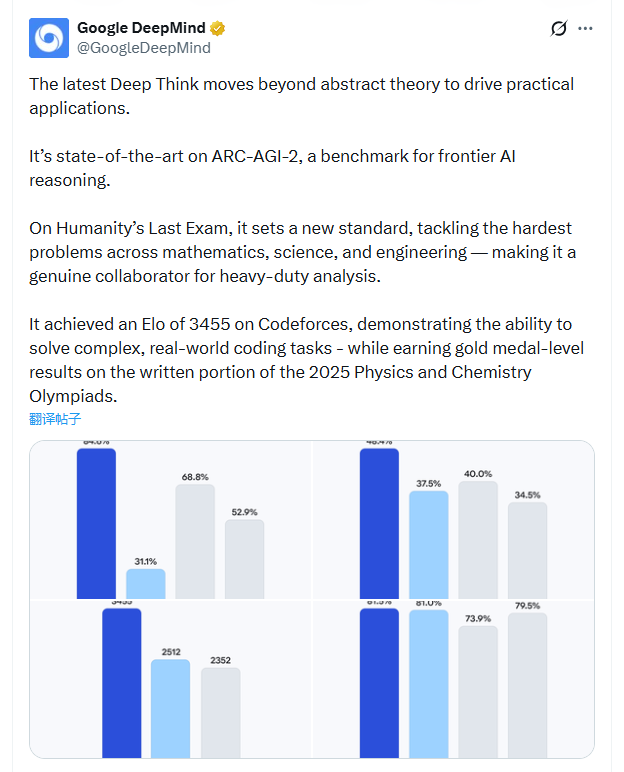
在算法竞赛平台Codeforces上,Gemini获得了3455的Elo评分。全球目前仅有七人保持更高分数。就在十二个月前,最强竞争AI模型的得分还停留在2727分,低了近700分。
"这不仅是渐进式改进",审阅结果的MIT计算机科学教授Elena Vasquez博士解释道,"它代表着AI系统处理复杂问题分解方式的质的飞跃"。
超预期的科学突破
该模型的分析能力远不止编程竞赛:
- 审稿超能力:在一篇已通过人工同行评审的高水平物理论文中发现了微妙的逻辑缺陷
- 数学造诣:成功证明了与著名Erdős猜想相关的多个难题
- 工程直觉:能将手绘草图转化为生产级3D模型文件(如笔记本支架),效率提升十倍
跨学科基准测试制霸
数据充分证明了Gemini的广泛能力:
- 在严苛的"终极人类考试"(HLE)中获得48.4%分数
- ARC-AGI-2基准测试准确率达84.6%
- 在STEM领域保持强劲表现的同时展现更强的创造性推理能力
目前该升级仅限AI Ultra订阅用户和通过API访问的特定研究人员使用,使谷歌在与竞争对手的推理模型对抗中占据强势地位。
关键要点:
- 编程:可与全球顶尖0.001%程序员比肩
- 科学分析:能发现连专家评审都忽略的错误
- 工程应用:彻底改变原型设计速度
- 可用性:目前仅限高级订阅用户和研究合作伙伴